
- Home
- Blog
- Google Crawler und Crawl-Budget: Der vollständige Guide
Der vollständige Guide: wie Google crawlt, welche Crawler es gibt, was das Crawl Budget bestimmt und wie du das Crawling möglichst gezielt steuerst.
Die neue Google-Dokumentation ist dabei keine tief technische Spezialanleitung, sondern eher ein komprimierter Überblick über Grundprinzipien, Zuständigkeiten und Grenzen des eigenen Crawlings. Genau das macht sie für SEO interessant, denn sie verdichtet einige Punkte, die in der Praxis oft missinterpretiert werden. Im folgenden Blogbeitrag schlüsseln wir das Thema für dich auf.
TL;DR: Google Crawler & Crawl-Budget
- Google crawlt das Web mit mehreren spezialisierten Bots, nicht nur dem Googlebot. Jeder hat einen eigenen User-Agent, eine eigene Aufgabe, und lässt sich separat per robots.txt steuern.
- Crawling ist Phase 1 vor Indexierung und Ranking. Wer hier Probleme hat, verliert, bevor das Spiel überhaupt beginnt.
- Häufiges Crawling ist ein Qualitätssignal – Google crawlt öfter, was Nutzer suchen und was sich aktualisiert. Seltenes Crawling ist kein Alarm, aber ein Hinweis, den man prüfen sollte.
- Das Crawl Budget bestimmt, wie viele Seiten Google pro Zeitraum crawlt. Es ergibt sich aus Servergeschwindigkeit (Crawl-Rate-Limit) und dem, was Google für relevant hält (Crawl-Bedarf). Für Websites unter 1000 Seiten ist es selten ein Problem. Ab 10 000 URLs mit Facetten-Navigation oder vielen technischen Duplikaten wird es kritisch.
- KI-Crawler sind eine eigene Kategorie. GPTBot, PerplexityBot, ClaudeBot und Google-Extended crawlen unabhängig von Google Search. Google-Extended blockieren kostet kein Ranking. KI-Crawler pauschal blockieren kostet GEO-Sichtbarkeit.
Was ist Google Crawling?
Google Crawling ist der automatisierte Prozess, mit dem Google neue Webseiten entdeckt, deren Inhalte analysiert und für die Aufnahme in den Suchindex vorbereitet. Kein Crawling, kein Ranking.
Der Prozess läuft in 3 aufeinanderfolgenden Phasen ab:
- Crawling: Automatisierte Systeme rufen URLs ab und lesen deren Inhalte
- Indexierung: Die gecrawlten Inhalte werden analysiert und in den Google-Index aufgenommen
- Ranking: Bei einer Suchanfrage bewertet und sortiert Google die indexierten Inhalte
Crawling ist Phase 1. Wer hier Probleme hat, verliert bereits vor dem Ranking.
Googles Crawler: Mehr als nur der Googlebot
Viele SEOs sprechen pauschal von „dem Googlebot“. Das ist ungenau. Google betreibt mehrere spezialisierte Crawler für unterschiedliche Zwecke:| Crawler | Zweck | User-Agent (Auszug) |
|---|---|---|
| Googlebot (Desktop) | Indexierung für Desktop-Suche | Googlebot/2.1 |
| Googlebot (Smartphone) | Mobile-First-Indexierung (Standard-Bot) | Googlebot (Smartphone) |
| Googlebot-Image | Google Images | Googlebot-Image/1.0 |
| Googlebot-Video | Google Video-Suche | Googlebot-Video/1.0 |
| Googlebot-News | Google News | Googlebot-News |
| AdsBot-Google | Qualitätsprüfung für Ads Landing Pages | AdsBot-Google |
| Google-Extended | Datenerhebung für KI-Modelle (Gemini) | Google-Extended |
Googles Crawler nutzen erkennbare User-Agents und verifizierbare IP-Adressen. Wer Logfiles analysiert, sollte nach Crawler-Typ differenzieren: Nicht alle Googlebot-Zugriffe haben dieselbe Funktion.
Konkret: In der Search Console unter Einstellungen > Crawl-Statistiken siehst du (in einer etwas anderen Benennung), welcher Crawler wie oft auf deine Seite zugegriffen hat. Abweichungen zwischen Typen können auf technische Probleme oder Crawl-Budget-Verschwendung hinweisen.
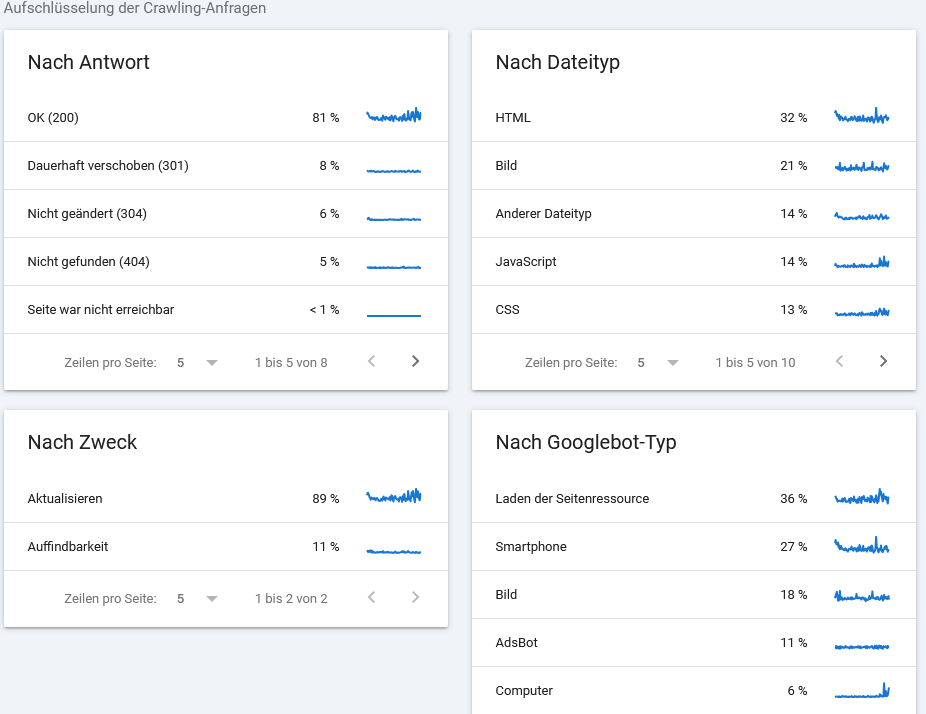
Häufiges Crawling: Was es bedeutet (und was nicht)
Googles Dokumentation enthält eine ungewöhnlich klare Aussage: Wenn Google eine Website häufig crawlt, ist das grundsätzlich ein positives Signal. Google verknüpft hohe Crawl-Aktivität mit 2 Faktoren:
- Frische Inhalte: Seiten, deren Inhalte sich regelmäßig ändern (Preise, Verfügbarkeiten, News)
- Nutzer-Nachfrage: Inhalte, nach denen Search-Nutzer aktiv suchen
Das Paradebeispiel: E-Commerce-Seiten werden häufiger gecrawlt, damit aktuelle Preise und Produktverfügbarkeiten in den Suchergebnissen erscheinen. Verzögerte Crawls würden zu veralteten Snippets führen.
Was häufiges Crawling nicht bedeutet: Es garantiert weder Indexierung noch gute Rankings. Der Zusammenhang ist eher umgekehrt: Seiten, die Search-seitig relevant sind, werden häufiger gecrawlt.
Konkret: Sehr wenige Googlebot-Zugriffe in den Logfiles sind kein Ranking-Killer, aber ein mögliches Warnsignal. Frage: Wird die Seite regelmäßig aktualisiert? Gibt es Indexierungsprobleme? Blockiert robots.txt relevante Seiten versehentlich?
Warum Google dieselbe URL mehrfach crawlt
Moderne Webseiten sind komplex. Google kann dieselbe URL mehrfach aufrufen, um ein vollständiges Bild zu erhalten:
- Erster Crawl: HTML-Grundstruktur erfassen
- Zweiter Crawl (Rendering): JavaScript-gerenderte Inhalte nachladen
- Weitere Crawls: Einzelne Ressourcen wie Bilder oder strukturierte Daten
Für JavaScript-lastige Websites (SPAs, React, Angular) ist das besonders relevant. Inhalte, die erst nach JS-Ausführung sichtbar werden, erreichen Google erst beim zweiten oder dritten Crawl. Manchmal gar nicht.
Konkret:
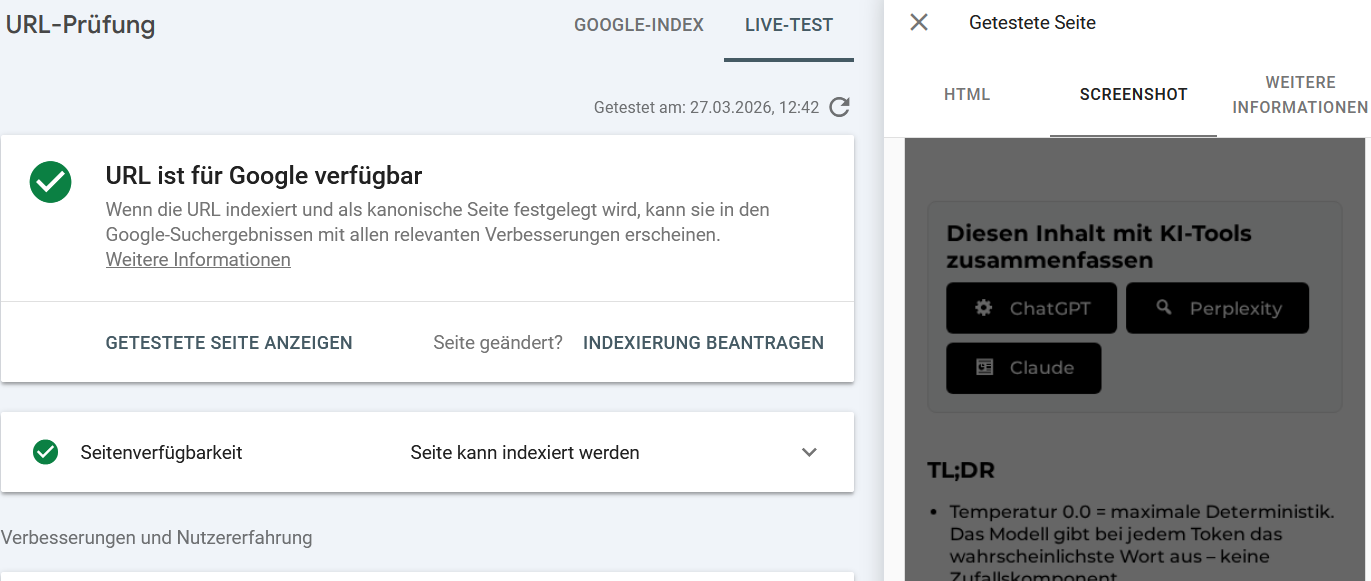
- Prüfe via Search Console > URL-Überprüfung > Live-Test, ob Google deine Seite gerendert sieht (siehe unten)
- Teste serverseitiges Rendering (SSR) oder Static Site Generation (SSG) für kritische Seiten
- Vermeide, wichtige Inhalte hinter Lazy-Load-Konstrukten zu verstecken
Was ist das Crawl Budget?
Nicht jede Seite einer Domain wird gleich häufig gecrawlt. Google verteilt seine Crawl-Kapazität dynamisch. Das Konzept: Crawl Budget.
Crawl Budget = Crawl-Rate-Limit × Crawl-Bedarf
| Faktor | Definition | Steuerung durch Site Owner |
|---|---|---|
| Crawl-Rate-Limit | Wie schnell darf Google crawlen, ohne den Server zu überlasten? | Indirekt: Servergeschwindigkeit und Antwortzeiten optimieren |
| Crawl-Bedarf | Wie viele Seiten bewertet Google als relevant und aktuell genug zum Crawlen? | Direkt: Content-Qualität, Linkstruktur, Aktualität |
Google passt beide Faktoren dynamisch in Echtzeit an. Steigt die Fehlerrate oder die Antwortzeit, reduziert Google die Crawl-Rate automatisch, ohne Vorwarnung.
Wann ist das Crawl Budget relevant? Für kleine Websites unter 1.000 Seiten mit schnellen Servern spielt es meist keine Rolle. Kritisch wird es bei:
- Websites mit mehr als 10.000 URLs
- E-Commerce-Shops mit Facetten-Navigation
- Nachrichtenseiten mit hohem Publikationsvolumen
- Websites mit vielen technischen Duplikaten
Wie berechnet Google das Crawl-Rate-Limit?
Google analysiert 3 Signale:
- Server-Antwortzeit: Unter 200 ms crawlt Google aggressiver. Über 500 ms drosselt Google spürbar.
- HTTP-Fehlerrate: Mehr als 5 % 5xx-Fehler reduzieren das Crawl-Rate-Limit.
- Historische Crawl-Daten: Google lernt aus vergangenen Sessions, wie viel eine Domain verträgt.
Das Crawl-Rate-Limit kannst du nicht manuell senken oder erhöhen. Die Suchmaschine empfiehlt bei der Notwendigkeit einer Senkung aber entweder die Ausgabe von einem Statuscode 500, 503 oder 429. Alternativ gibt es auch einen Report, den du melden kannst (weiter unten verlinkt).
Die neun größten Crawl-Budget-Killer
| # | Faktor | Auswirkung | Erkennungsmethode | Fix |
|---|---|---|---|---|
| 1 | Facetten-Navigation ohne Canonical | Hunderte bis Millionen parametrisierter URLs | Search Console > Indexabdeckung > nicht indexiert | Canonical auf Hauptkategorie; noindex auf Filtervarianten |
| 2 | Redirect-Ketten (3+ Hops) | Jeder Hop kostet Crawl-Budget und verlangsamt den Crawl | Screaming Frog > Response Codes > 3xx-Chains | Direkte Redirects auf finale URL |
| 3 | Session-IDs in URLs | Identischer Content unter Millionen verschiedener URLs | Logfile-Analyse; Search Console > URL-Muster | Session-IDs entfernen oder via robots.txt blockieren |
| 4 | Interne Links auf 404-Seiten | Crawler-Zeit für tote Seiten verschwendet | Screaming Frog > Response Codes > 4xx | Tote Links bereinigen; 301 auf relevante Zielseiten |
| 5 | Langsame Seiten (> 2s TTFB) | Google drosselt automatisch | Search Console > Core Web Vitals; GTmetrix | Server-Caching, CDN, Datenbankoptimierung |
| 6 | Duplizierter Content ohne Canonical | Crawler erschöpft sich an Varianten statt Unique Content | Siteliner; Screaming Frog > Duplicate Content | Canonicals konsequent setzen |
| 7 | Orphan Pages (kein interner Link) | Seiten ohne interne Links werden selten gecrawlt | Screaming Frog > Orphan Pages-Report | Relevante interne Links auf verwaiste URLs setzen |
| 8 | Zu große XML-Sitemaps (> 50k URLs) | Parsing-Overhead; nicht alle URLs werden verarbeitet | Search Console > Sitemaps > Fehler | Sitemaps aufteilen (< 10.000 URLs je Datei) |
| 9 | robots.txt blockiert Ressourcen | CSS/JS blockiert > Rendering unmöglich > keine Indexierung | Search Console > URL-Überprüfung > Screenshot | Ressourcen in robots.txt freigeben |
Crawl-Budget-Audit: 10-Punkte-Checkliste
Bevor du optimierst, benötigst du eine Baseline. Diese Prüfschritte liefern sie:
- Google Search Console > Crawl-Statistiken: Wie viele URLs crawlt Google täglich? Trend steigend oder sinkend?
- Search Console > Indexabdeckung: Wie viele URLs sind gecrawlt, aber nicht indexiert? (Signal für Budget-Verschwendung)
- Logfile-Analyse: Welche URLs crawlt Google am häufigsten? Sind das deine wichtigen Seiten?
- robots.txt prüfen: Blockiert die Datei CSS, JS oder relevante Inhaltsbereiche versehentlich?
- Redirect-Ketten identifizieren: Screaming Frog oder Sitebulb > alle 3xx-Chains mit 3+ Hops auflisten
- Duplicate-Content-Scan: Siteliner oder Screaming Frog > prozentualer Anteil duplizierten Contents
- Parametrisierte URLs prüfen: Logfiles zeigen, ob Filtervarianten gecrawlt werden
- Orphan Pages identifizieren: Screaming Frog > nicht intern verlinkte URLs
- Sitemap-Qualität prüfen: Sind alle URLs in der Sitemap crawlbar und indexiert? Das kannst du gut im Index-Report der Search Console einsehen.
- Server-Antwortzeiten messen: Antwortzeit < 200 ms unter Last ist das Ziel; Für eine detaillierte Analyse nutzt du am besten externe Tools (bspw. GTMetrix). Der Bereich Core Web Vitals in der GSC liefert ebenfalls Anhaltspunkte.
Crawl Budget optimieren: Die wichtigsten Hebel
Priorität 1: Budget-Killer eliminieren
Redirect-Ketten auflösen, tote Links bereinigen, parametrisierte URLs via robots.txt oder Canonical konsolidieren. Das sind die schnellsten Gewinne.
Priorität 2: Crawl-Bedarf steigern
Mehr Seiten regelmäßig aktualisieren (Datum im HTML sichtbar und dateModified im Schema), hochwertige interne Verlinkung auf wichtige Seiten aufbauen (siehe hierzu unseren Beitrag zur internen Link-Matrix), Backlinks für priorisierte URLs entwickeln.
Priorität 3: Server-Performance verbessern
Ziel: Time to First Byte (TTFB) unter 200 ms. Ein schneller Server erlaubt Google, mehr Seiten pro Zeiteinheit zu crawlen, ohne die Drosselungs-Grenze zu erreichen.
Priorität 4: Sitemaps strukturieren
Separate Sitemaps für Haupt-Content, News, Bilder und Videos. Jede Sitemap unter 10.000 URLs. Sitemaps in der Google Search Console einreichen und regelmäßig auf Fehler prüfen.
Login-Walls, Paywalls und gesperrte Inhalte
Google crawlt ohne spezielle Freigabe keine Inhalte hinter Login-Schranken oder Paywalls. Für Inhalte, die trotzdem indexiert werden sollen, gibt es dokumentierte Lösungen:
- Flexible Sampling: Menschlichen Nutzern nach X Artikeln eine Paywall zeigen, Google aber vollständigen Zugriff erlauben (mit Schema-Auszeichnung)
- Lead Wall: Vorschau öffentlich, Rest hinter Login. Via Preview Controls steuerbar.
- Kein Cloaking: Googlebot andere Inhalte zeigen als menschlichen Nutzern ist ein klarer Verstoß gegen Googles Spam-Richtlinien.
KI-Crawler: Wer crawlt neben Google?
Seit 2023 sind zahlreiche KI-Crawler aktiv, die Content für LLM-Training und KI-Antworten sammeln. Für GEO-Zitierbarkeit ist entscheidend, wer Zugriff hat.| KI-Crawler | Betreiber | Zweck | robots.txt-Blockierung |
|---|---|---|---|
| GPTBot | OpenAI (ChatGPT) | LLM-Training und Retrieval | User-agent: GPTBot |
| PerplexityBot | Perplexity AI | Echtzeit-Suche und Quellenauswahl | User-agent: PerplexityBot |
| ClaudeBot | Anthropic | LLM-Training | User-agent: ClaudeBot |
| Google-Extended | KI-Modelltraining (Gemini) | User-agent: Google-Extended | |
| Applebot-Extended | Apple | KI-Features (Apple Intelligence) | User-agent: Applebot-Extended |
| Bytespider | ByteDance / TikTok | LLM-Training | User-agent: Bytespider |
Google-Extended zu blockieren beeinflusst das Ranking in der Google-Suche nicht. Wer KI-Trainingsdaten schützen will, kann Google-Extended separat sperren, ohne Ranking-Nachteile.
Beispiel robots.txt für selektives Blocking:
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Disallow: /premium/
Für GEO: Wer in KI-Antworten zitiert werden will, sollte KI-Crawler nicht pauschal blockieren. Perplexity, ChatGPT und Gemini können Inhalte nur referenzieren, wenn ihre Crawler Zugriff hatten. Siehe zu diesem Thema auch unseren Beitrag „LLMs und SEO„.
Steuerung: Was du als Site Owner kontrollieren kannst
| Tool | Funktion | Wichtigste Einschränkung |
|---|---|---|
| robots.txt | Crawl-Zugriff erlauben oder sperren | Blockiert Crawling, nicht Indexierung |
| Robots-Meta-Tag | Indexierung und Darstellung steuern (noindex, nofollow, nosnippet) | Wird nur gelesen, wenn die Seite gecrawlt wird |
| Sitemaps | Neue und aktualisierte URLs priorisiert melden | Kein Ranking-Signal, hilft aber der Crawl-Effizienz |
| Search Console | Crawl-Statistiken, Probleme, manuelle URL-Überprüfung | Reaktiv, keine direkte Crawl-Rate-Steuerung |
Fragen und Antworten rund um Google Crawler und Crawl Budget
Was macht der Googlebot genau?
Der Googlebot ist ein automatisiertes Programm (Spider/Crawler), das URLs aufruft, deren HTML-Inhalte liest und neue Links entdeckt, um diese ebenfalls zu crawlen. Er kann JavaScript ohne zusätzlichen Rendering-Schritt nicht ausführen.Wie oft crawlt Google meine Website?
Das hängt vom Crawl Budget ab. Kleine Websites mit wenigen Seiten werden möglicherweise täglich gecrawlt. Große Domains mit Millionen URLs können Wochen auf einen vollständigen Crawl-Zyklus warten, wenn überhaupt. Aktuelle Inhalte (News, E-Commerce) werden häufiger gecrawlt als statische Seiten.
Mehr Tipps? Kostenlosen SMART LEMON SEO-Newsletter abonnieren!
Was ist der Unterschied zwischen Crawling und Indexierung?
Crawling: Google besucht die URL und liest den Inhalt. Indexierung: Google speichert und verarbeitet diesen Inhalt für die Suche. Eine gecrawlte Seite ist nicht automatisch indexiert. Eine indexierte Seite wurde jedoch immer gecrawlt.Wie sehe ich mein Crawl Budget in der Search Console?
Dein Crawl-Budget kannst du nicht direkt einsehen. Eine Annäherung findest du aber in der Google Search Console > Einstellungen > Crawling-Statistiken. Dort siehst du Crawl-Anfragen pro Tag (letzte 90 Tage), durchschnittliche Antwortzeit und Dateigröße, aufgeschlüsselt nach Crawler-Typ. Und apropos Dateigröße: Seit Februar 2026 gilt ein neues 2‑MB-Crawling-Limit bei Google. Prüfe also unbedingt, wie groß deine Dateien sind.
Kann ich mein Crawl Budget erhöhen?
Direkt nicht. Google bestimmt das Budget. Indirekt kannst du es verbessern: Servergeschwindigkeit erhöhen, Budget-Killer eliminieren, interne Verlinkung optimieren und Seiten regelmäßig aktualisieren.Beeinflusst das Crawl Budget Rankings direkt?
Nicht direkt. Wenn wichtige Seiten nicht gecrawlt werden, können sie nicht indexiert werden, und eine nicht indexierte Seite hat kein Ranking. Crawl Budget ist ein notwendiges, kein hinreichendes Ranking-Signal.Kann ich bestimmte KI-Crawler blockieren, ohne Google-Rankings zu verlieren?
Ja. Google-Extended, GPTBot und andere KI-Crawler können in robots.txt separat gesteuert werden. Das Blockieren von Google-Extended beeinflusst weder Crawling noch Ranking in der Google-Suche.Wie schnell indexiert Google eine neue Seite?
Sehr unterschiedlich: von einigen Minuten/Stunden bei gut verlinkten News-Seiten bis zu mehreren Wochen bei neuen Domains ohne Backlinks. Die schnellste Methode ist die URL-Überprüfung in der Search Console mit manuellem Indexierungsantrag.
Was passiert, wenn Google meine Seite nicht crawlen kann?
Seiten, die nicht gecrawlt werden (z. B. durch robots.txt blockiert oder durch Server-Fehler unerreichbar), können nicht indexiert werden. Rendering-Probleme durch JavaScript können dazu führen, dass nur Teile des Inhalts indexiert werden.Sollte ich KI-Crawler im Crawl Budget berücksichtigen?
KI-Crawler wie GPTBot oder PerplexityBot haben kein Crawl Budget im SEO-Sinne: Sie crawlen unabhängig von Google. Für GEO-Zitierbarkeit solltest du sicherstellen, dass diese Bots in robots.txt nicht blockiert sindund alle relevanten Inhalte auch sehen/erfassen können.
Weitere Informationen und Quellen zum Crawling bei Google
- Google Developers: About crawling – auf: developers.google.com am: 3. März 2026 (englisch)
- Google Developers: Crawl Budget – auf: developers.google.com am: 19. Dezember 2025 (englisch)
- Google Search Central: robots.txt-Spezifikation – auf: developers.google.com am: 10. Dezember 2025 (englisch)
- Gary Illyes: What crawl budget means for Googlebot – auf: developers.google.com (englisch)
- Google Search Console Hilfe: Crawl Stats report – auf: support.google.com (englisch)
- OpenAI: GPTBot user agent – auf: platform.openai.com (englisch)
- Perplexity AI: PerplexityBot – auf: docs.perplexity.ai (englisch)
- Chris Long: Technical SEO News: Google released a „Things To Know About Web Crawling“ doc that details crawling basics + best practices – auf: linkedin.com am: 6. März 2026 (englisch)
- Google Search Console: Problem mit übermäßigem Crawling melden (deutsch/englisch)

David startete 2016 als Trainee bei SMART LEMON. Gestartet mit einem redaktionellen Hintergrund, ist er mittlerweile Senior SEO Manager und bespielt alle Bereiche der Suchmaschinenoptimierung: von Technik über Content bis Strategie.