Crawling-Fehler mit der Google Search Console verstehen & beheben
Aktualisiert: - Veröffentlicht: - Autor: Oskar Eder

- Home
- Blog
- Crawling-Fehler mit der Google Search Console verstehen & beheben
Inhaltsverzeichnis
Der GSC-Report „Crawling-Statistiken“ ist wahrscheinlich das am meisten unterschätzte Tool, das du nicht in deinen täglichen SEO-Workflow integriert hast. Das mag sicherlich auch daran liegen, dass Google diese Daten gut im Menü versteckt hat.
Wir erklären dir im Detail, welche Daten dieser Report liefert und wie du diese Informationen zur Optimierung deiner Seite nutzen kannst. In Kombination mit dem Indexierungs-Report lässt sich hier eine ganze Menge anstellen.
Wo liegt der Crawling-Bericht in der GSC?
Der Bericht ist zugegebenermaßen etwas versteckt, obwohl er doch essenzielle Erkenntnisse liefern kann. Bist du in der GSC angemeldet, scrolle im Menü links an den Verbesserungen-Reports vorbei bis zu den Einstellungen. Dort finden sich in der Übersicht der Punkt „Crawling“.
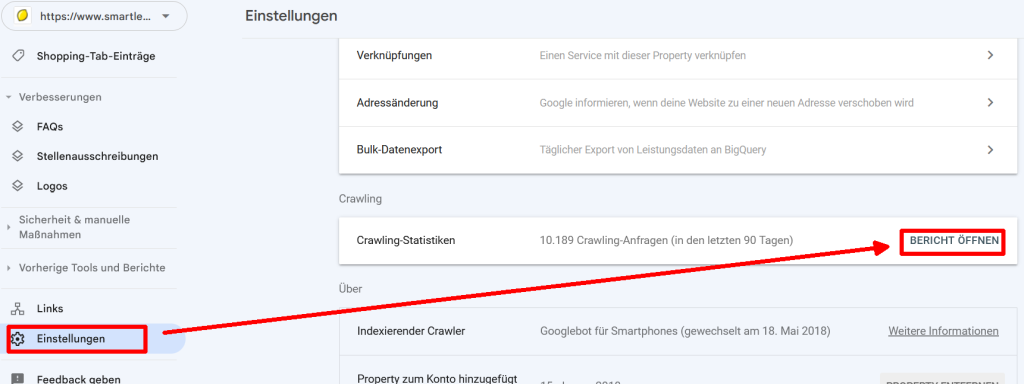
Der Crawling-Bericht findet sich im Bereich „Einstellungen“.
Welche Daten liefert der Bericht zur Crawling-Statistik der GSC?
Google hat diesen Bericht im Vergleich zu den vergangenen Jahren DEUTLICH verbessert. Obwohl er nicht perfekt ist, kann er eine Menge Informationen darüber liefern, wie Google deine Website crawlt. Aus SEO-Sicht ist dies hilfreich, wenn kein oder nur sehr aufwendig Zugang zu den Server-Log-Files besteht. Wenn du hier die Daten der Google Search Console nutzt, ist das kein Ersatz, aber zumindest eine Alternative.
Ein paar Informationen zum Report vorab: Der Crawling-Bericht zeigt ausschließlich die Daten der jeweils letzten 90 Tage. Hierin enthalten sind auch nur die URLs, die Google auch wirklich anforderte. Kanonische URLs zählen nicht dazu. Bei Weiterleitungsketten zählt der Report alle Anfragen auf die einzelnen, weitergeleiteten Seiten. Des Weiteren wertet der Bericht nur Ressourcen aus, die auf der infrage stehenden Domain liegen. Bspw. Bilder, die andere Websites hosten, zählen dementsprechend nicht dazu. Anfragen zwischen Subdomains fließen in den Bericht ein, wenn er von der übergeordneten Domain ausgeht. HTTPS- bzw. HTTP-Varianten spielen für die Auswertung des Berichts keine Rolle. Der Übersicht halber liefert der Bericht in allen Bereichen repräsentative Beispiel-URLs.
Die Übersichtsseite der Crawling-Statistiken
Hier kannst du verschiedene Statistiken darüber abrufen, wie Google mit deiner Website interagiert. Der Einstieg in den Report erfolgt über eine Übersichtsgrafik mit allen Crawling-Anfragen, der gesamten Downloadgröße in Byte und der durchschnittlichen Reaktionszeit in Millisekunden. Die Crawling-Anfragen beinhalten auch mehrfache Anfragen an eine einzelne URL.
Die Downloadgröße berechnet sich aus den Größen aller Dateien und Ressourcen, die der Googlebot herunterlädt. Dazu zählen bspw. der HTML-Code einer Datei, Bilder, Skripte und CSS-Dateien. Die durchschnittliche Reaktionszeit (Seitenantwortzeit) zeigt an, wie lange eine Seite beim Abruf eines Seiteninhalts bei einer Crawling-Anfrage benötigt. Nicht zu verwechseln mit der Rendering-Zeit. Der gesamte Report steht als Excel-, CSV- oder Google Sheets-Export zur Verfügung. Übrigens: Mit dem Update des 2MB-Crawl-Limits aus dem Februar 2026 sollte das Thema Größe der Dateien stärker in deinen Fokus rücken.
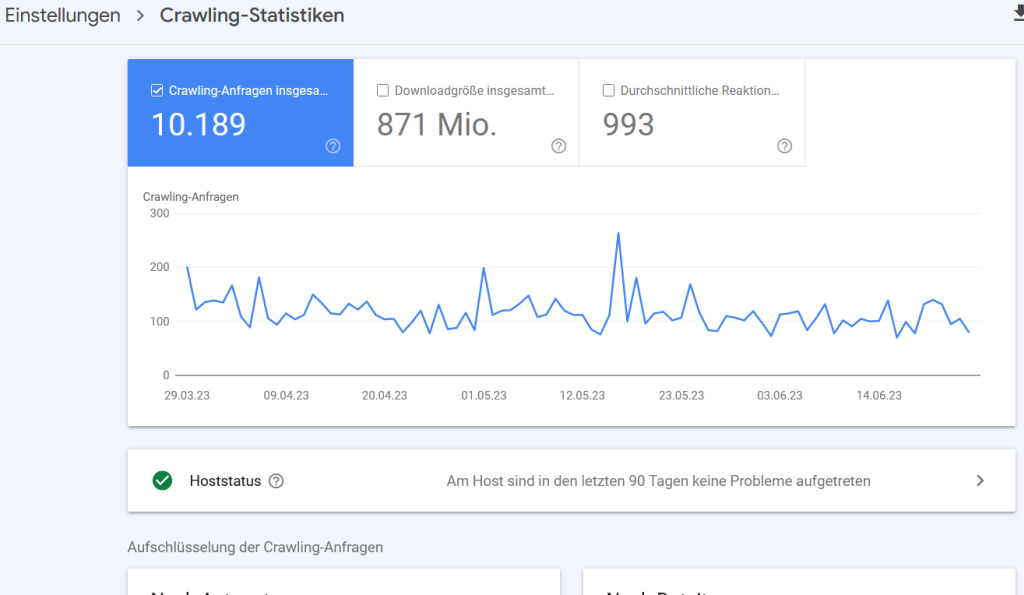
Übersichtsseite der Crawling-Statistiken.
1. Grafische Darstellung im zeitlichen Verlauf über 90 Tage
Gibt es an bestimmten Terminen Spitzen oder Rückgänge in den Crawl-Trends? Hier lohnt es sich, diese Crawl-Trends im Auge zu behalten, um mögliche Probleme beim Crawlen oder serverbezogene Probleme zu erkennen.
2. Gibt es Probleme mit dem Host-Status?
Der Host-Status ermöglicht es dir, die Verfügbarkeit Deiner Website in den vergangenen 90 Tagen zu überprüfen. Schaue hier nach, ob Google Probleme beim Crawlen Deiner Website hatte. Im Normalfall sollte hier – wenn es keine technischen Probleme gab – alles im grünen Bereich sein.
Ein weiterer Vorteil dieses Reports: Wenn du deine Website als Domain-Property hinterlegt hast, liefert Google dir hier auch eine Übersicht aller Host bzw. Subdomains des Projekts. Auch gilt, dass deren Status über die letzten 90 Tage überprüft wird. Dies ersetzt zwar kein klassisches Server-Monitoring, kann dir im Falle der Fälle aber wichtige Hinweise geben, falls die Suchmaschine Probleme erkennt.
3. Aufschlüsselung der Crawling-Anfragen
Den letzten Teil des Crawling-Berichts gruppiert die GSC in vier Bereiche: Antwort, Dateityp, Zweck und Googlebot Typ. Zu Beginn ein wichtiger Hinweis zur Darstellung. Standardmäßig zeigt die GSC hier jeweils immer nur fünf Zeilen pro Report an. Dies wohl aus Gründen der Übersichtlichkeit. Insofern solltest du auf jeden Fall die Darstellung erweitern und prüfen, ob noch weitere Auffälligkeiten vorhanden sind.
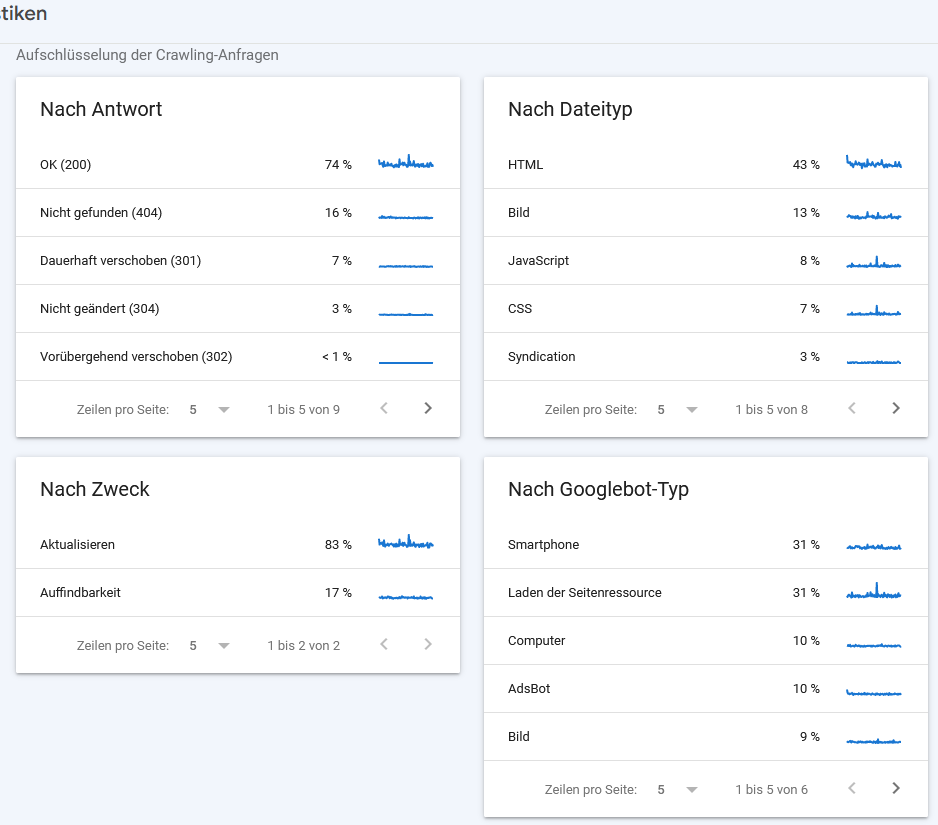
Aufschlüsselung der Crawling-Anfragen nach Antworten, Dateityp usw.
Folgende Reports stehen dir zur Verfügung:
a) Nach Antwort (HTTP Statuscodes)
Hier sind die Ergebnisse nach http-Status-Code sortiert. Die GSC liefert hier prozentuale Angaben, die sich immer auf die Gesamtzahl der Crawling-Anfragen beziehen. Prüfe, ob Googlebot auf eine hohe Anzahl von 3xx- oder 4xx-Antworten stößt. Im Folgenden ein Praxisbeispiel, wie du diese Informationen zur Optimierung deiner Seite nutzen kannst:
Öffne den entsprechenden Report für die 4xx-Fehler. Google zeigt dann eine detaillierte Liste der letzten URLs mit entsprechenden Datumsangaben. Diese Daten ziehst du dir dann als Export und wandelst sie in Excel oder Google Sheets in eine Pivot-Tabelle um. Auf diese Weise kannst du sehen, welche Fehlerseiten Googlebot am häufigsten versucht zu crawlen und dementsprechend die Fehlerbehebung priorisieren. Du solltest hier direkt prüfen, ob die URL ggf. noch in der XML-Sitemap vorhanden ist und es auf deiner Seite nicht noch interne Verlinkungen auf diese fehlerhaften URLs gibt.
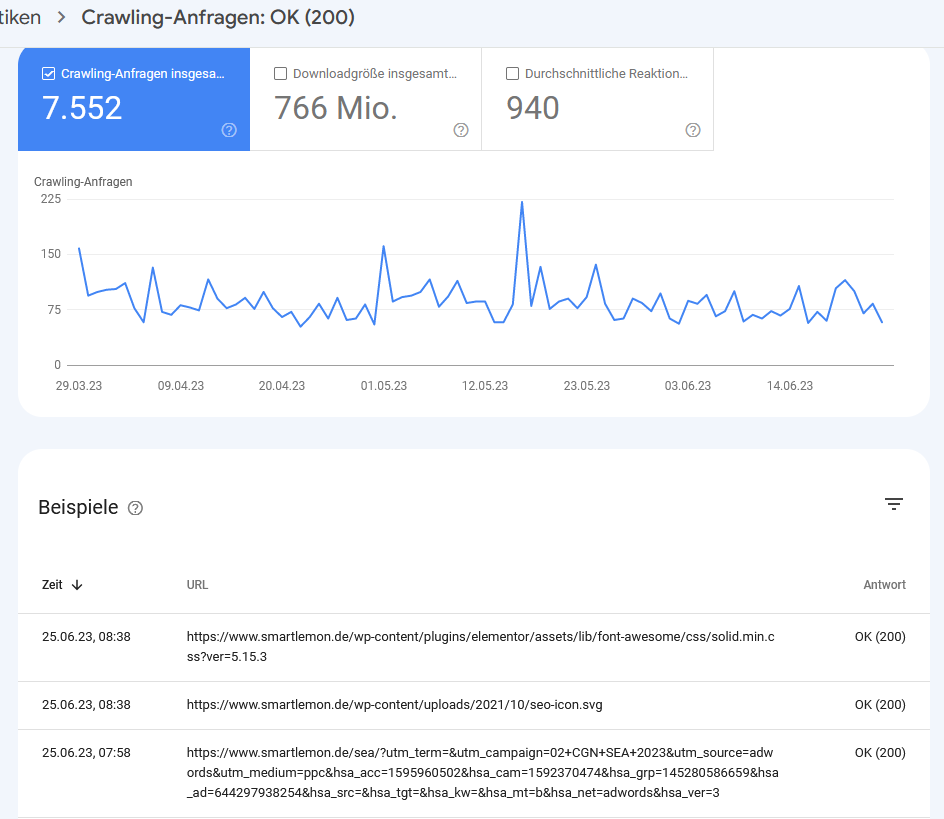
Detail-Ansicht für alle 200er-Anfragen.
|
|
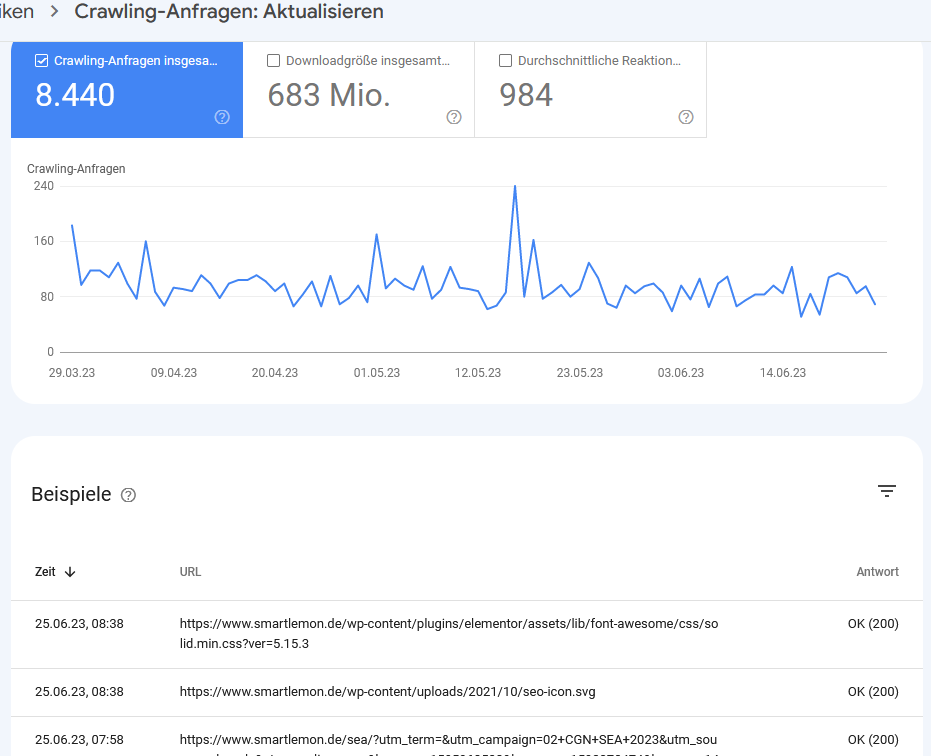
Detail-Ansicht für den gefilterten Report nach Crawling-Anfragen zur Aktualisierung.
c) Aufschlüsselung der Crawling-Anfragen nach Dateityp
Welche Dateitypen deine Website bei einer Crawling-Anfrage zurückgibt, hängt (Überraschung) natürlich davon ab, welche Dateien du verwendest. In diesem Report siehst du, welche Ressourcen (HTML, Bilder, Videos,…) von Google am meisten gecrawlt werden und ob dies zu Crawling-Problemen wie einer langsameren Antwortzeit führt. Falls Google unverhältnismäßig viele merkwürdige Dateitypen crawlt, könnte es sich lohnen, dem nachzugehen. Hinweis: Sind Bilder und Videos Seitenressourcen, kommt dafür der Bot „Laden der Seitenressource“ zum Einsatz.
Es ist auch möglich, dass die GSC hier “Anderer XML-Dateityp” angibt. Das sind überwiegend XML-Dateien ohne RSS oder KML (Format zum Speichern geografischer Daten). Andere, hier nicht weiter spezifizierte Dateitypen, fasst der Crawling Bericht unter “Anderer Dateityp” zusammen. Sollte eine Crawling-Anfrage auf eine Datei fehlschlagen, spricht die GSC hier von “Unbekannt”.
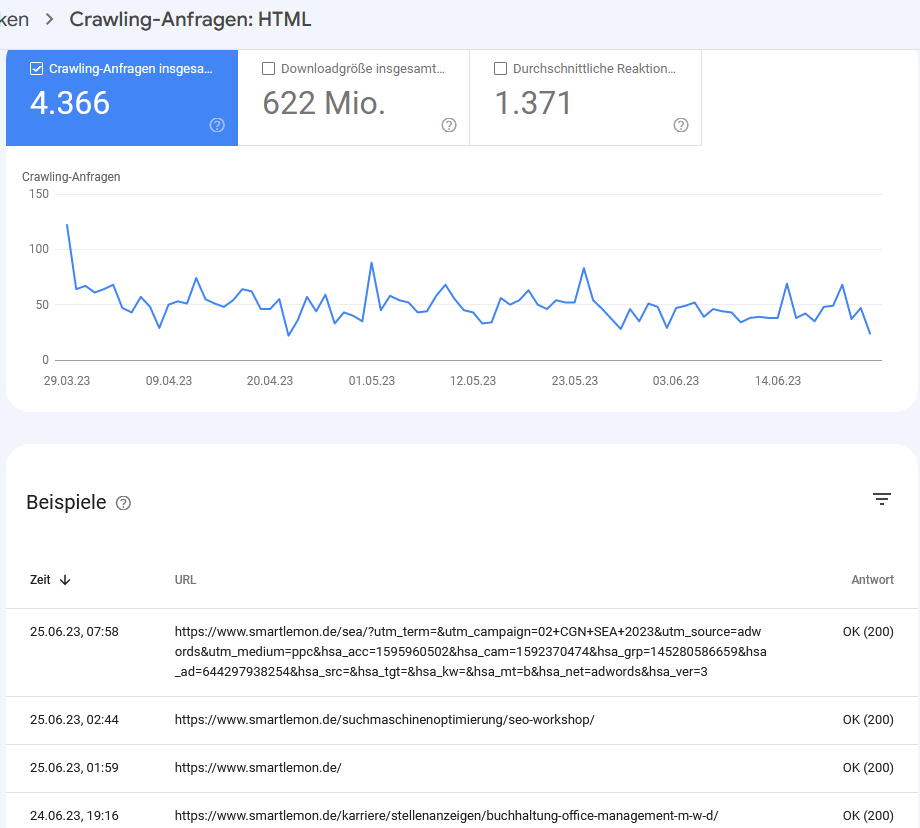
Detail-Ansicht für die Crawling-Anfragen nach Datei-Typ.
d) Nach Googlebot-Typ
Hier kannst du sehen, welche Googlebots/User Agents die Website crawlen. Achte auf etwaige Schwankungen, insbesondere bei der Ressourcenbelastung der Seiten, da dies auf ein Darstellungsproblem hinweisen könnte.
Google nutzt hier acht verschiedene User Agents für verschiedene Zwecke (Smartphone, Computer, Laden der Seitenressource – zum Rendern genutzt – etc.). Mehr zu diesem Thema findest du übrigens auch in unserem großen Google-Crawling-Guide.
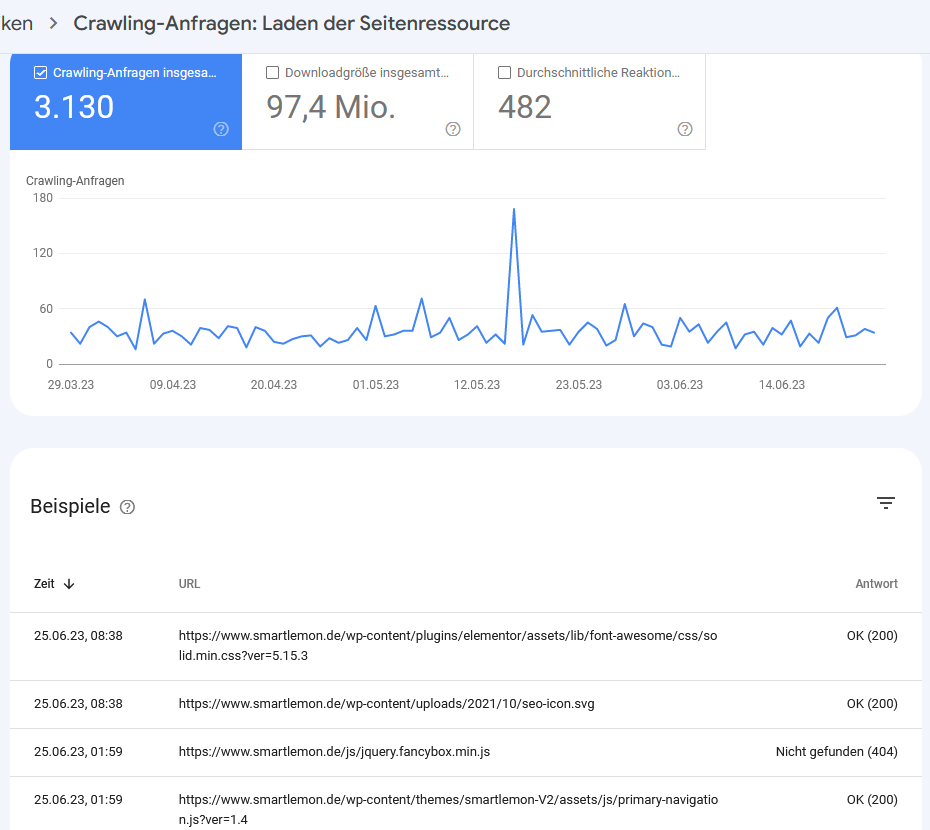
Detail-Ansicht für die Crawling-Anfragen nach Googlebot-Typ.

Fazit
Lange mussten sich SEOs und Webmaster mit einem eher mageren Bericht zu Crawling-Statistiken zufriedengeben. So lieferte der alte Report der GSC lediglich Daten zur Anzahl der gecrawlten Seiten, der heruntergeladenen Dateigröße sowie zur durchschnittlichen Reaktionszeit. Es blieb also nichts anderes übrig, als Vermutungen aufzustellen, was genau der Googlebot denn crawlte. Da ist der neue Report schon etwas detaillierter (und die Kombination mit den Indexierungs-Reports der Google Search Console auch sinnvoll).
Es ist trotzdem empfehlenswert, noch weitere Analyse-Tools hinzuzuziehen. Denn Google spielt im neuen Crawling-Report nur eine Auswahl aller URLs aus. Der beste und detaillierteste Weg bleibt also immer noch die Analyse der Log Files. Wer darüber hinaus verstehen möchte, wie KI-Dienste wie ChatGPT Search, Bing Copilot oder Perplexity Inhalte crawlen und anzeigen, findet in unserem großen Guide zu LLMs und SEO alle wichtigen Informationen.
Übrigens: Wie du ganz allgemein deinen organischen Traffic mit dem Leistungs-Report analysiert, findest du ebenfalls in unserem Blog.
Weiterführende Informationen und Quellen zur GSC – Crawling-Statistiken

Im Jahr 2023 das erste Mal etwas von SEO gehört - seit August 2024 Teil des SMART LEMON Teams. Als Werkstudent vorrangig im Bereich SEO & GEO kümmert sich Oskar um Analysen, Keyword-Recherchen und Onpage-Optimierungen im Bereich der Suchmaschinenoptimierung.