Google indexiert deine Seite nicht? So prüfst du das mit der Google Search Console
Aktualisiert: - Veröffentlicht: - Autor: Oskar Eder

- Home
- Blog
- Google indexiert deine Seite nicht? So prüfst du das mit der Google Search Console
Inhaltsverzeichnis
Wir können es nicht laut und oft genug sagen: Die Google Search Console ist dein bester Freund:in, wenn du SEO auch nur ansatzweise betreiben willst. Viele kennen aber (immer) noch nicht den vollen Leistungsumfang des Tools, das die Suchmaschine uns netterweise sogar komplett kostenlos (und DSGVO-konform) zur Verfügung stellt.
Zeit, das zu ändern! Wir zeigen dir heute, wie du Indexierungsprobleme mit der Google Search Console erkennst und behebst.
Indexierung
Beginnen wir mit dem wichtigsten Aspekt: Die Überprüfung, ob Google auch die richtigen URLs indexiert. Die GSC liefert dir dafür eine ganze Reihe passender Reports unter:
GSC → Indexierung → Seiten (oder direkt von der Startseite der GSC → Seitenindexierung)
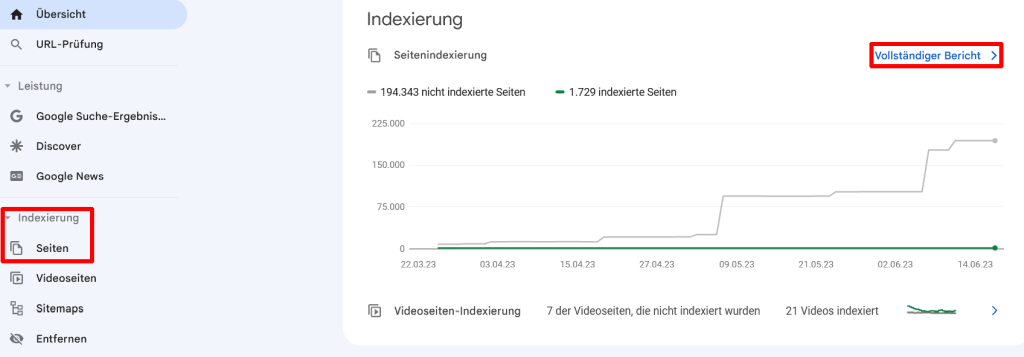
Einstieg entweder über die Startseite („Vollständiger Bericht“) oder links über die Sidebar.
Hier findest du eine grundsätzliche Zweiteilung in Seiten, die indexiert sind und solche, die es nicht sind. Einige Propertys haben zusätzlich auch einen Abschnitt mit „Darstellung von Seiten verbessern“. Hierzu empfehlen wir dir unseren Artikel zu den Verbesserungs-Reports in der Google Search Console. Standardmäßig beziehen sich die angezeigten Daten auf alle Seiten, die Google bekannt sind. Du kannst dir aber auch nur alle eingereichten (oder nicht eingereichten) Seiten anzeigen lassen – mehr dazu auch im Abschnitt “Sitemaps prüfen”. Grundsätzlich empfehlen wir sowohl einen Blick auf indexierte als auch nicht indexierte Seiten. Im Folgenden konzentrieren wir uns aber auf die häufigsten Gründe, warum Seiten nicht indexiert werden.
Report „Indexierte Seiten“
Werden die einzelnen URLs deiner Domain indexiert, ist damit die Grundvoraussetzung erfüllt, dass du damit Rankings und hoffentlich auch Traffic über die organische Suche generierst (zur Detail-Analyse siehe unseren Artikel „Organischen Traffic analysieren mit dem Leistungs-Report„). Trotzdem solltest du hier kritisch prüfen, ob nicht auch unnötige URLs wie Tags, Archive, die interne Suche, parametrisierte URLs indexiert werden. Gerade CMS-Systeme wie WordPress & Co bringen von Haus aus eine Vielzahl an automatisch generierten URLs mit, die parallel zu den eigentlichen URLs nichts im Index zu suchen haben.
Tipp: Exportiere die Liste der URLs aus diesem Report in Google Tabellen. Dort kannst du nämlich auch mit regulären Ausdrücken arbeiten – die Filtermöglichkeit in der GSC bietet das nicht an. Prüfe, ob sich hier Muster in der URL-Struktur erkennen lassen. Entweder mit Verzeichnissen wie /tag/, /rss/, /feed/, /atom/, /author/ oder mit an die URLs angehängten Parametern, die in der Regel mit einem “?” beginnen. Also etwa: “?utm_source=” usw. holst, solltest du das ggf. mit angeben.
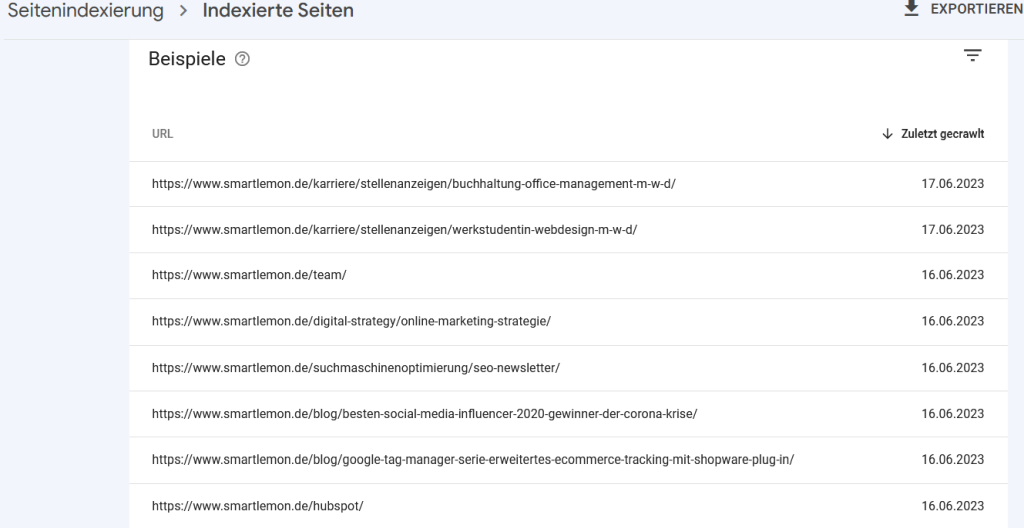
Beispiel: Korrekt indexierte Seiten – die auch im Index sein sollen.
Warum ist das sinnvoll?
Es sollten nur die URLs in den Index der Suchmaschine gelangen, die tatsächlich relevant sind. Zu viele unnötige Seiten können dazu führen, dass die wichtigen Inhalte seltener oder im schlimmsten Fall gar nicht gecrawlt und damit indexiert werden.
„Seiten“-Report: Verhältnis zwischen indexierten und nicht indexierten Seiten
Tauchen im zuvor genannten Report sehr viele URLs auf, die nicht indexiert werden? Hier immer das Verhältnis zur Anzahl der Indexierten zu den ausgeschlossenen URLs im Auge behalten. Je nach Struktur der Domain dürfte ein Großteil der ausgeschlossenen URLs korrekt sein, trotzdem solltest du kritisch prüfen, ob hier alles seine Richtigkeit hat. Ggf. findest du hier auch Seiten, die du eigentlich im Index haben möchtest. Ferner solltest du dir anschauen, ob sich hier nicht Muster in den URLs erkennen lassen, die du grundsätzlich entfernen kannst. Sprich, warum muss Googlebot beispielsweise über jede Weiterleitung oder Archiv-Seite (siehe oben) gehen.
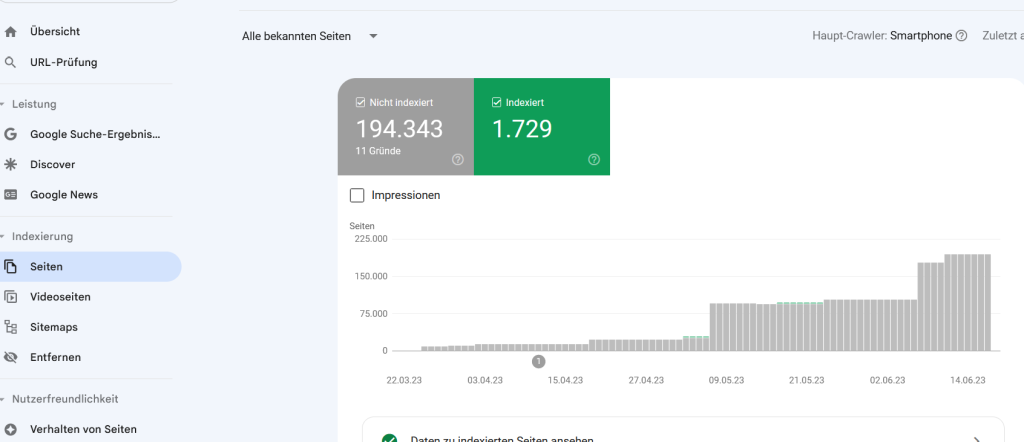
Problematisches Verhältnis zwischen nicht-indexierten und indexierten Seiten.
Warum ist das sinnvoll?
Google crawlt zunächst einfach los – unabhängig davon, ob eine URL indexiert werden soll oder nicht oder ob sie für dich wichtig ist. Prüfe deshalb zum Beispiel, dass du nicht indexierbare Seiten intern verlinkst. Schließlich willst du, dass die Suchmaschine die wichtigen URLs schnell indexiert. Übrigens: Mehr zum Verhalten findest du in unserem Google-Crawling-Guide.
„Duplikat – vom Nutzer nicht als kanonisch festgelegt“
Der Report “Duplikat – vom Nutzer nicht als kanonisch festgelegt” liefert uns Antworten auf die Frage, ob Google deine als kanonisch gesetzten URLs tatsächlich auch für den Index heranzieht. Im vorliegenden Report findest du alle URLs, bei denen Google von der Vorgabe/Empfehlung des hinterlegten Canonical-Tags abweicht und eine andere Variante als passender bewertet. Dementsprechend solltest du deine Canonical-Tags im Quellcode und CMS prüfen.

Beispiel: Von Google selbst als Duplikat eingestufte URLs.
Warum ist das sinnvoll?
Du solltest für Google Eindeutigkeiten schaffen. Dazu gehört auch, dass es technisch gesehen nur eine Version einer bestimmten URL gibt. Ist das nicht der Fall, kann es zu solchen Duplikaten kommen – und Google nimmt einfach eine Version deiner Seite. Das obige Beispiel zeigt ein etwas anderes Problem, nämlich wenn interne Suchen ständig gecrawlt werden, weil sie „nur“ per Canonical auf eine andere URL zeigen, statt via robots.txt ausgeschlossen zu werden.
„Durch „noindex“-Tag ausgeschlossen“
Es gibt zahlreiche Gründe, weshalb eine URL eine “noindex”-Angabe enthält. In der Regel auch völlig zurecht. So haben etwa automatisch generierte Archiv-Seiten nichts im Index zu suchen. Trotzdem: Überprüfe sicherheitshalber, ob eine wichtige URL von dir nicht doch zufällig auf “noindex” steht. Wenn es mehrere URLs betrifft, schau nach, ob hier nicht ein übergreifendes Problem vorliegt
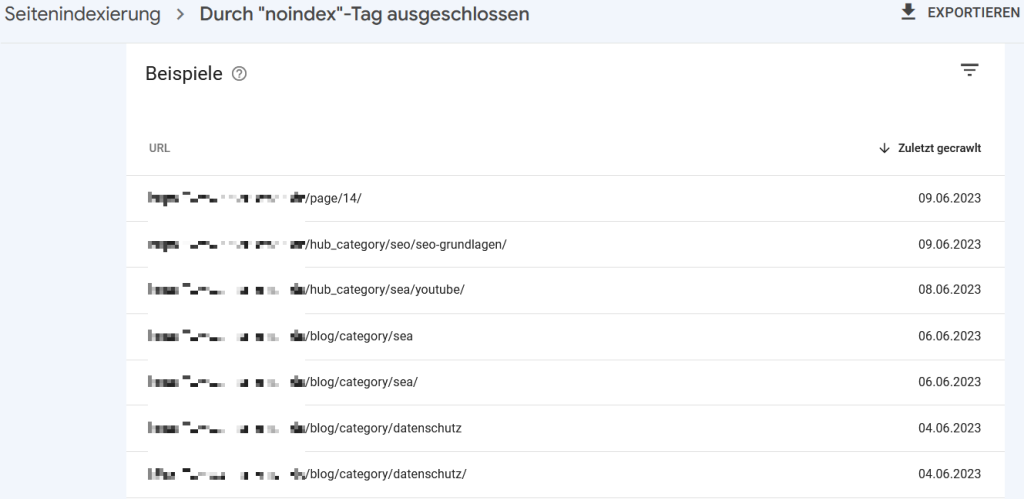
Klassisches Beispiel: Vom CMS generierte Kategorie- und Paginierungs-Seiten, die korrekt auf noindex stehen.
Weshalb ist das wichtig?
Falsche noindex-Angaben passieren öfter, als du denkst. Deswegen ist ein Blick in diesen Report immer gut. Denn wenn eine URL nicht im Index ist, kann sie auch keinen organischen Traffic produzieren. Hier auch nochmal als Erinnerung: Stell sicher, dass solche URLs keine internen Relevanz-Signale erhalten. Im obigen Beispiel ergibt es zum Beispiel keinen Sinn, diese Art von Archiv-Seiten intern zu verlinken – weil sie eben auf noindex stehen.
„Nicht gefunden (404)“
Ein Klassiker: Welche URLs sind nicht mehr erreichbar? Ein 404-Fehler ist zunächst vollkommen normal und nichts Schlimmes. Enthält diese Liste aber URLs, die es noch geben sollte und/oder deren Inhalte sich mittlerweile auf einer anderen URL befinden, solltest du tätig werden.

In dem Fall irrelevante 404-Fehler, für die keine Weiterleitungen nötig sind.
Weshalb ist das wichtig?
Du solltest der Suchmaschine eine möglichst “saubere” Domain liefern. Das heißt beispielsweise auch, keine 404-URLs intern zu verlinken oder per Sitemap zu kommunizieren. Wirf hier einen Blick rein und prüfe, ob diese URLs als 404-Fehler in Ordnung sind oder ob du sie weiterleiten kannst.
„Durch robots.txt blockiert“
Welche URLs deiner Domain hast du durch Angaben in deiner robots.txt vom Crawling ausgeschlossen? Häufig findest du hier vom CMS automatisch generierte URLs, interne Suchen und mehr. Prüfe dennoch, ob sich hier URLs finden, die für dich eigentlich wichtig sind.
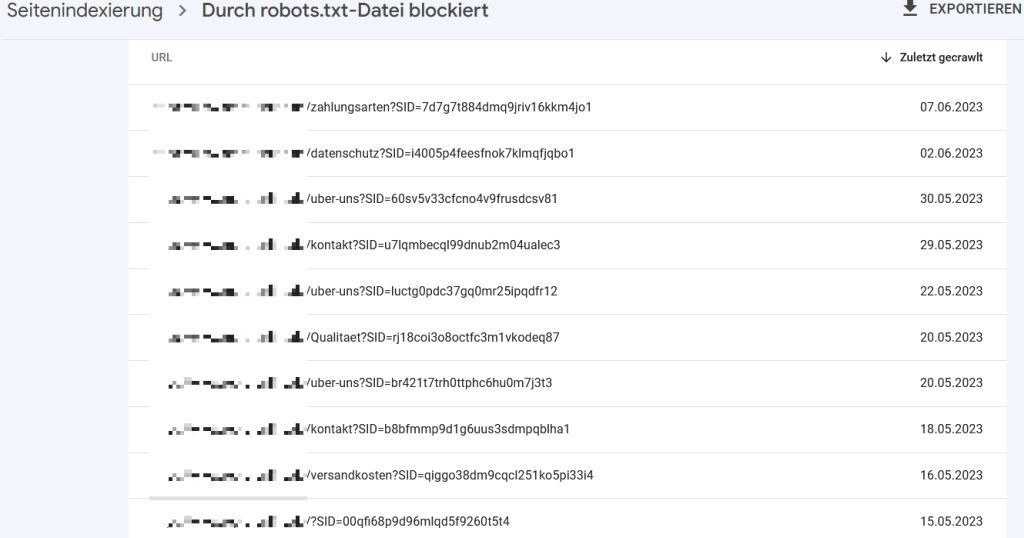
Beispiel: URL-Parameter, die durch Angaben in der robots.txt blockiert sind.
Weshalb ist das wichtig?
Wichtige Unterscheidung: Wenn du eine URL vom Crawling via robots.txt ausschließt, bedeutet das nicht, dass sie nicht auch indexiert werden kann. Trotzdem ist es möglich, dass genau das die Konsequenz davon ist. Auch wenn viele CMS automatisch eine korrekte robots.txt generieren, gilt es, diese immer noch einmal zu prüfen.
“Gefunden – zurzeit nicht indexiert” / “Gecrawlt – zurzeit nicht indexiert”
Seit einiger Zeit informiert Google dich auch über URLs, die sie entweder gefunden oder sogar schon gecrawlt, aber noch nicht indexiert haben – oder sie waren indexiert, mittlerweile aber nicht mehr. „Gefunden – zurzeit nicht indexiert“ teilt dir dabei mit, dass der Bot diese URL zwar kennt, aber noch nicht gecrawlt hat – eine Inhaltsbewertung hat also noch nicht stattgefunden. Bei „Gecrawlt – zurzeit nicht indexiert“ ist die URL schlichtweg noch nicht in den Index aufgenommen. Anders ausgedrückt: Aus irgendeinem Grund stuft die Suchmaschine diese Inhalte als nicht so relevant an, um sie in den Index zu nehmen. Hast du in diesen Fällen alle inhaltlichen Hebel verwendet, um die Relevanz dieser URL zu verdeutlichen? Neben Content und interner Verlinkung spielen auch technische Faktoren wie Ladegeschwindigkeit, Layout-Stabilität oder, sehr wichtig, die Größe einer Datei eine Rolle. Denn ist dein HTML-Dokument über 2MB groß, indexiert Google je nachdem nur Teile davon. Mehr dazu in unserem Artikel zum 2MB-Crawl-Limit für Googlebot.
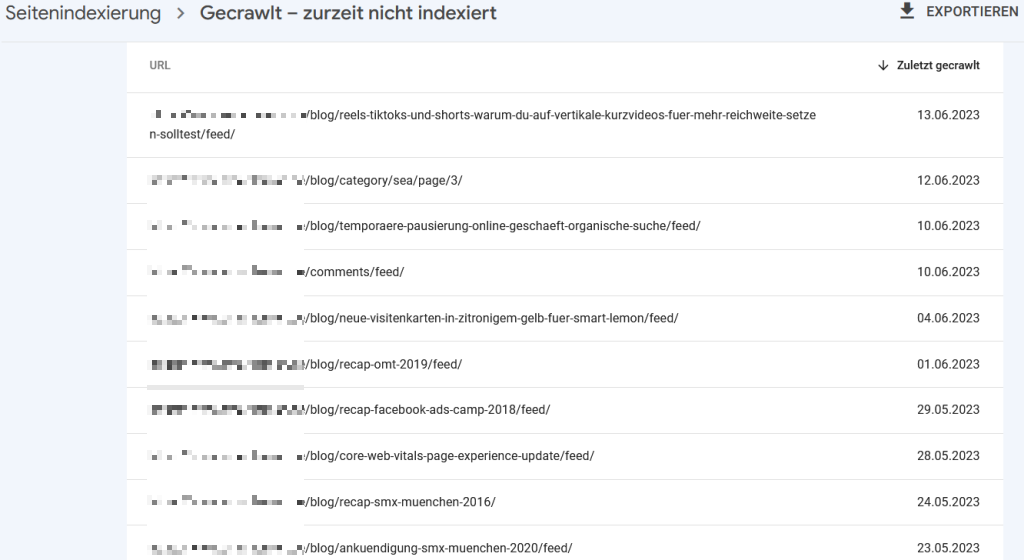
Beispiel: URLs, die gecrawlt, aber nicht indexiert sind. Die meisten haben keine Relevanz, weil es vom CMS generierte URLs sind.
Weshalb ist das wichtig?
Wenn du neue URLs veröffentlichst, willst du sie in der Regel auch möglichst schnell indexieren lassen. Fallen diese Seiten aber lange Zeit in diesen Report, gilt es zu prüfen, ob du Google deren Relevanz noch verdeutlichen kannst – zum Beispiel durch eine bessere interne Verlinkung, bessere Inhalte und/oder Snippets.
Report „Sitemaps“
Im Report “Sitemaps” kannst du eine oder mehrere XML-Sitemaps hinzufügen. Nützliches Feature: Die zuvor genannten Reports kannst du mit einem Klick auf “Seitenindexierung ansehen” auf eine spezifische Sitemap herunterbrechen. Falls Google Probleme mit der Verarbeitung der Datei hat, erhältst du hier eine entsprechende Nachricht.

Der Sitemap-Report in der Search Console. Bei Klick auf die drei Punkte neben einer Datei öffnet sich ein Dropdown, was dich wiederum zum „Seiten“-Report zurückbringt – ausschließlich mit den Seiten, die in dieser Sitemap enthalten sind.
Weshalb ist das wichtig?
Mit dem Einreichen einer XML-Sitemap kannst du mehr Kontrollmöglichkeiten innerhalb der Google Search Console nutzen. Gleichzeitig kannst du so die Relevanz hinsichtlich des Crawlings dieser URLs an Google kommunizieren.

Fazit
Mit den Indexierungs-Reports in der Search Console erhältst du schon sehr detaillierte Informationen darüber, warum Google eine URL indexiert oder nicht, und welche Fehler vorliegen. Zum Großteil geht es hier um technische Punkte, aber wie du gemerkt hast, spielen auch inhaltliche Themen (Stichwort Relevanz) eine Rolle. Zusammen mit der Sitemaps bzw. der Möglichkeit, die dargestellten Seiten nach Sitemaps (und/oder allen bekannten Seiten) filtern, ergibt das eine gute Kombination, um den Indexierungsstatus deiner wichtigsten Inhalte zu überprüfen.
Ein weiterer Tipp: Die Crawling-Statistiken in der Google Search Console sind zwar recht versteckt, aber wirklich hilfreich – gerade in Kombination mit den Daten aus dem Indexierungs-Report.
Weiterführende Informationen und Quellen zum Indexierungs-Report

Im Jahr 2023 das erste Mal etwas von SEO gehört - seit August 2024 Teil des SMART LEMON Teams. Als Werkstudent vorrangig im Bereich SEO & GEO kümmert sich Oskar um Analysen, Keyword-Recherchen und Onpage-Optimierungen im Bereich der Suchmaschinenoptimierung.