
- Home
- Blog
- Logfile-Analyse im Kontext von LLMs
Inhaltsverzeichnis
Die Logfile-Analyse ist ein bewährtes Tool der Suchmaschinenoptimierung. Und hier zeigt sich, dass für viele Websites die organische Suche nach wie vor der größte Traffic-Lieferant ist.
Aber in den Logfiles tauchen neue KI-Crawler auf: GPTBot, Perplexity, Claude & Co. Was holen sie sich? Welche Inhalte bevorzugen sie? Die Antwort steckt in deinen Server-Logs. Dieser Beitrag zeigt, wie aus Logfile-Signalen, einem SEO-Crawl und einem Colab-Skript eine Entity-Heatmap entsteht, und wie du damit für KI-Antworten und generative Ergebnisse sichtbarer wirst.
TL;DR
- Warum du KI-Traffic analysieren solltest: KI-Crawler siehst du in GA4 nicht. Andere Trackingmöglichkeiten liefern ein besseres Bild – am besten sind hier Logfiles.
- KI-Crawler vs. Googlebot: GPTBot & Co. verhalten sich oftmals komplett anders als klassische Suchmaschinen. Sie rendern kein JavaScript, ignorieren Sitemaps und fokussieren gezielt Inhalte mit Frage-Antwort-Potenzial. Dadurch bleiben clientseitig gelieferte oder schlecht verlinkte Seiten für KI unsichtbar.
- So analysierst du Bots richtig: Kombiniere GA4-Referrals, Bot-Tracking-Tools wie Dark Visitors und Server-Logfiles (z. B. über den Screaming Frog Log File Analyzer). So bekommst du ein umfassendes Verständnis darüber, wie Bots crawlen, wann sie aktiv sind und wie der Kanal performt.
- Von der Analyse zur Strategie: Mit unserem Google-Colab-Skript erstellst du in wenigen Minuten eine „Entity-Heatmap“, die dir zeigt, welche Themen KI-Bots besonders oft besuchen. Nutze diese Daten, um Content gezielt zu erweitern, strukturierte FAQs einzubauen und deine Seiten sowohl für Menschen als auch für KI-Systeme zu optimieren.
KI-Crawler vs. Googlebot: Unterschiede im Crawl-Verhalten
Über Jahre haben wir SEOs gelernt, Googlebot zu verstehen. Google’s Crawler folgt brav den Links, achtet auf die robots.txt, berücksichtigt XML-Sitemaps, rendert bei Bedarf JavaScript und kehrt regelmäßig zurück, um Inhalte zu aktualisieren. Das Verhalten ist gut dokumentiert und relativ vorhersehbar. Google selbst liefert einige Einblicke inzwischen auch über die Google Search Console. KI-Bots hingegen stehen noch am Anfang ihrer Entwicklung und weichen in ihrem Crawl-Verhalten teilweise erheblich von Googlebot ab.
Ein wesentlicher Unterschied: KI-Crawler priorisieren nicht zwingend dieselben Inhalte oder Techniken wie Google. Wie wir in unserem Beitrag zur Sichtbarkeit in ChatGPT & Co. ausführen, ist ein anschauliches Beispiel dafür das JavaScript-Crawling und Rendering: So führen z.B. OpenAI’s Bots (wahrscheinlich aus Kostengründen) kein JavaScript aus. Auch XML-Sitemaps zur Erschließung von URLs und Informationsarchitekturen verwenden sie nicht. Das heißt, rein clientseitig gelieferter Content oder Seiten ohne interne/externe Verlinkung bleiben höchstwahrscheinlich unsichtbar. Lange Rede, kurzer Sinn: Während Googlebot über die Jahre gelernt hat, komplexe Websites zu crawlen, sind KI-Crawler (noch) sehr limitiert.
Google durchsucht das Web, um ein Ranking aufzubauen und Nutzer dann auf Websites zu schicken. KI-Systeme hingegen crawlen, um Inhalte selbst zum Beantworten von Fragen (Answer Engines) oder zum Trainieren von Modellen zu nutzen. Dies spiegelt sich auch im Crawl-Verhalten wider: KI-Bots steuern gezielt nur bestimmte Seitentypen oder Seitenabschnitte an, die für häufige Fragen relevant sind. Alles andere wird dann ignoriert oder spielt eine untergeordnete Rolle. Für SEOs gilt daher: Der Fokus von KI-Crawlern und klassischen Suchmaschinen kann sich deutlich unterscheiden.
Dein Ansatz zur Analyse von KI-Crawlern (und -Traffic)
Um zu verstehen, wie sich KI-Crawler verhalten, musst du diese Bots analysieren. Mit einem klassischen Tool zur Messung von Besuchern auf deiner Website (bspw. Google Analytics 4) kommst du nicht weit, auch wenn es sinnvolle Anwendungsfälle dafür gibt. Folgende Übersicht zeigt dir Vor- und Nachteile:
| Ansatz | Stärken | Schwächen |
|---|---|---|
| KI-Referral-Tracking per GA4 | Misst Engagement und Conversions/Umsatz. | Erfasst menschliche Sitzungen direkt, Bots jedoch nicht (höchstens Näherungen möglich). Manuelles Set-up nötig. |
| Bot-Tracking-Tools (bspw. Dark Visitors) | Echtzeit-Tracking aller Bots und menschlicher Referrals, automatische Alerts. | Externes Tool, ggf. zusätzliche Kosten. Kein Blick auf Conversions, Umsatz etc. Begrenzte historische Tiefe. |
| Auswertung von Server-Logfiles (Analyse bspw. durch Screaming Frog Log File Analyser) | Voller Zugriff auf Rohdaten, tiefe technische Einblicke. | Manuelles Importieren, keine Live-Daten. Kein Blick auf Conversions, Umsatz etc. Limitierte Free-Version. |
- GA4 misst Impact auf Umsatz, sieht aber keine Bots (bzw. erfasst nur Nutzer, die über KI-Dienste auf die Seite gekommen sind – siehe hierzu auch unseren LLMs-SEO-Guide).
- Bot-Tracking-Tools wie Dark Visitors zeigt KI-Präsenz in Echtzeit und gibt einen guten Überblick.
- Server-Logfiles sind die “wahre” Sicht. Eine Verarbeitung mit Tools wie dem Screaming Frog Log File Analyzer liefert den mit Abstand tiefsten Blick. Wenn du tiefer in die technische Auswertung einsteigen möchtest, findest du in unserem Beitrag zur Logfile-Analyse SEO konkrete Tipps zu Crawl-Budget, KI-Bots, Statuscodes und Performance-Signalen.
Exkurs: So misst du den Erfolg von KI-Referrals
- Alle KI-Aufrufe (ChatGPT-User, OAI-Searchbot, GPTBot usw.) aus Logfiles filtern.
- Diese mit Analytics- und/oder CRM-Daten verknüpfen. Hier dann explizit darauf achten, nur den entsprechenden Kanal bzw. den richtigen Referrer zu filtern.
- Grundsätzlich kannst du dir damit KPIs wie die Conversion-Rate berechnen.
Hier wird es Ungenauigkeiten geben, weil sich nicht alle Daten perfekt zuordnen lassen. Diese Näherungswerte helfen dir trotzdem weiter und zeigen, ob dein KI-generierter Traffic wirklich besser konvertiert.
Übrigens: Die Frage, inwiefern KI-generierter Traffic besser konvertiert (und daher besonders wertvoll ist), beantworten aktuelle Studien sehr unterschiedlich. Ein Grund mehr also, die eigenen Daten zu prüfen.
Beispiele für unterschiedliches Crawling-Verhalten (lt. DarkVisitors)
Im Laufe einer Woche lassen sich sehr unterschiedliche Muster und Crawling-Verhalten über alle Arten von Bots hinweg feststellen. Wir haben hier sowohl die Daten aus dem Tool DarkVisitors (s. Screenshot unten) als auch die der Logfiles ausgewertet.
Häufigkeit der Visits verschiedener Bots
Hier ist eine Übersicht der Bots mit den anteilig meisten Aufrufen (Zeitraum: 16.10.2025 – 22.10.2025):
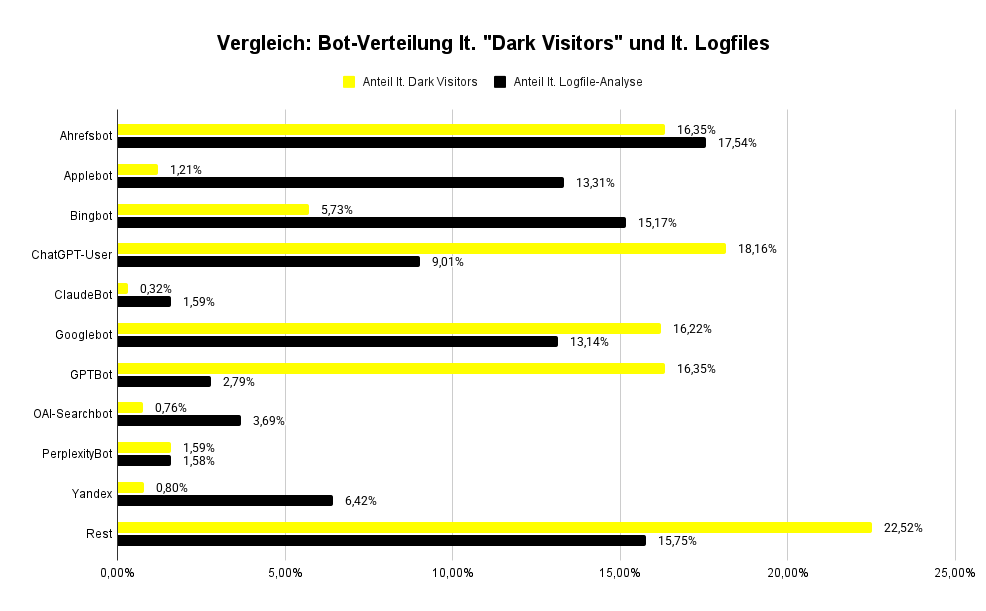
Auffällig hier, dass sogar noch vor dem Googlebot ein SEO-Crawler anteilig die meisten Visits vornimmt. Einige LLM-Crawler wie ChatGPT-User oder der OAI-SearchBot finden sich hier auch, wenn auch mit deutlich weniger Besuchen.
Verteilung der meistbesuchten URLs aller Crawler
- Googlebot verteilt seine Aufrufe relativ gleichmäßig. Die meistbesuchte URL war die Startseite mit ca. 6 % aller Hits.
- Beim Bingbot war eine ähnliche Verteilung zu beobachten. Am meisten aufgerufen hier: die XML-Sitemap und der aktuelle Beitrag zum Start des Google AI Mode.
- Eine extrem gleichmäßige Verteilung gibt es beim OAI-Searchbot. Bis auf die Startseite entfiel jeder Hit auf eine andere URL.
- Das andere Extrem ist ChatGPT-User: Fast 40 % aller Visits gingen auf die Startseite.
Weitere Daten und Vergleiche findest du in diesem Google Sheet.
Was bringt mir ein tieferer Blick in diese Daten überhaupt?
Ein Zufallsfund unterstreicht, warum solche Daten so sinnvoll und hilfreich sind. Bei Betrachtung der am meisten aufgerufenen Seiten fiel uns folgende URL ins Auge: /recap-seo-day-2019/
Die URLs gibt es allerdings nicht mehr (404-Fehler). Normalerweise ein klarer Fall für eine Weiterleitung. Bei einer tieferen Analyse zeigt sich aber, dass vorrangig ein einziger SEO-Crawler die URL immer wieder versucht abzurufen. Alle anderen Crawler beachten die Seite so gut wie gar nicht.
Wichtig: robots.txt und KI-Crawler
Die meisten KI-Crawler halten sich an Vorgaben der robots.txt. Zumindest OpenAI hat bestätigt, dass sein GPTBot den Standard-Disallow-Regeln folgt. Trotzdem sollte man Crawl-Statistiken vergleichen, welche Statuscodes Googlebot generiert und welche die KI-Bots erzeugen. Finden KI-Crawler z. B. vermehrt 403/Forbidden-Seiten, hast du vielleicht Bereiche per robots.txt oder .htaccess/IP-Regeln für alle Bots gesperrt? Oder der KI-Bot ruft ständig Parameter-URLs auf und gerät in Endlosschleifen, anders als Googlebot, der sie durch Canonicals vermeidet.
Übrigens: Für einen genaueren Blick auf die Googlebots empfehlen wir auch immer die Crawling-Statistiken in der Google Search Console. Hier werden die User-agents zwar nicht so genau genannt, aufgrund der verschiedenen Crawling-Anfragen kann man trotzdem Rückschlüsse ziehen.
Ebenfalls wichtig: Verwechsle die robots.txt nicht mit der llms.txt. Das ist ein relativ neuer Ansatz, um KI-Crawlern wichtige Informationen bereitzustellen. Mehr dazu im Beitrag „KI-Sichtbarkeit steigern: GEO-Maßnahmen im Praxistest„.
Wichtige KI-Bots auf einen Blick
Große KI-Plattformen setzen unterschiedliche Bots ein. Da OpenAI/ChatGPT aktuell den größten Marktanteil einnimmt, sind folgende Bots vor allem wichtig:
- GPTBot: Für ChatGPT-Training.
- OAI-SearchBot: Für aktive Websuchen.
- ChatGPT-User: Ruft Inhalte direkt bei Nutzerfragen ab (zeigt Live-Zitate).
Daneben spielen auch Perplexity (PerplexityBot) und natürlich Google (GoogleExtended, Google-NotebookLM, Gemini-Deep-Research) eine Rolle.
Ein Praxisbeispiel: Unsere Logs zeigen für 7 Tage:
- ChatGPT-User: 473 Abrufe
- PetalBot (Huawei): 182 Aufrufe
- PerplexityBot: 45 Aufrufe
- GPTBot: 20 Aufrufe
- OAI-Searchbot: 17 Aufrufe
Kleiner Tipp: Bots findest du in Logfiles relativ schnell per Regex (z. B. nach „GPTBot|ChatGPT-User|ClaudeBot“ suchen). Eine praktische Auflistung aller Bots inklusive einer Kategorisierung nach AI Bot, Suchmaschine usw. gibt es übrigens auch auf der DarkVisitors-Website sowie über das “ai.robots.txt”-github-Projekt (beides am Ende des Beitrags verlinkt). Die wichtigsten LLM-Crawler inklusive der User-Agent-Strings haben wir hier aufgeführt:
| Name | User Agent String | Nutzen |
|---|---|---|
| Applebot | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot) | Apples Web-Crawler, der Inhalte für Spotlight, Siri und Safari indexiert (AI-Search-Crawler). |
| CCBot | Mozilla/5.0 (compatible; CCbot/2.0; +http://commoncrawl.org/faq/) | Common Crawls Crawler zum Aufbau eines offenen Web-Datensatzes für Forschung, Analyse und KI-Training (AI-Data-Scraper). |
| ChatGPT-User | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot | Assistenten-Zugriff: ruft Seiten gezielt ab, wenn ChatGPT-Nutzende während eines Chats Web-Informationen anfordern (keine systematische Indexierung). |
| Google-Extended | Mozilla/5.0 (compatible; Google-Extended/1.0; +http://www.google.com/bot.html) | Googles Crawler für das Sammeln von Inhalten zur KI-Nutzung/-Schulung (z. B. Gemini, Vertex AI; AI-Data-Scraper). |
| GPTBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot) | OpenAIs Crawler zum Sammeln öffentlich zugänglicher Inhalte für das Training von Modellen wie ChatGPT (AI-Data-Scraper). |
| OAI-SearchBot | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot | OpenAIs Such-Crawler (für SearchGPT): indexiert Web-Inhalte für KI-gestützte Suchergebnisse (AI-Search-Crawler). |
| PerplexityBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot) | Perplexity AIs Such-Crawler: indexiert Inhalte zur Bereitstellung von Echtzeit-Antworten in der Perplexity-Suche (AI-Search-Crawler). |
Was will GPTBot? Erstelle eine KI-Heatmap deiner Website in 3 einfachen Schritten
Mit diesem Guide erstellst du in wenigen Minuten eine „semantische Heatmap“, die dir genau zeigt, welche Themenschwerpunkte deiner Website für KI-Systeme am relevantesten sind.
Was du benötigst
- Screaming Frog SEO Spider (Version 20+): Ein Crawl, bei dem die Inhalt-Embeddings aktiviert sind (Configuration > Content > Embeddings).
- Kostenpflichtiger API-Key für OpenAI (ChatGPT) oder Google (Gemini), um die Embeddings beim Crawl zu extrahieren
- Screaming Frog Log File Analyzer: Ein Export der Log-Daten aus dem „URLs“-Tab.
- Unser Google Colab Skript: Der Link, der die ganze Arbeit für dich erledigt.
Deine KI-Heatmap in 3 Schritten
Schritt 1: Skript öffnen und konfigurieren- Öffne unser fertiges Google Colab Skript über diesen Link und erstelle dir über „Datei -> Kopie in Drive speichern“ eine eigene Kopie.
- Passe ganz oben die interaktiven Felder an. Lege fest, welche Bots du analysieren und wie viele semantische Themen (Cluster) das Skript aus deinen Embeddings finden soll. Die Standardwerte sind ein guter Start.
Schritt 2: Skript starten & Dateien hochladen
Klicke auf den „Play“-Button, um das Skript zu starten. Es wird dich nacheinander auffordern, deine CSV-Dateien hochzuladen:
- Zuerst der Screaming Frog Export (die internal_all.csv mit der Embedding-Spalte).
- Danach der Log File Analyzer Export (die CSV aus dem „URLs“-Tab).
- Optional der Google Search Console Export (wenn du Nutzerdaten vergleichen willst).
Das Skript erkennt automatisch die Embedding-Spalte und beginnt mit der KI-gestützten Cluster-Analyse.
Schritt 3: Ergebnisse analysieren & Report herunterladen
Nach Abschluss der Analyse erscheinen die Ergebnisse direkt im Notebook:
- Visuelle Heatmap (s. Screenshot unten): Erkenne auf einen Blick, welche deiner semantischen Themen-Cluster bei den Bots am beliebtesten sind.
- Top-Listen: Sieh dir an, welche URLs die meisten Bot-Hits bekommen und wo ungenutztes „Content-Potenzial“ liegt.
- Download-Button: Klicke auf den grünen Button, um den vollständigen Excel-Report mit allen Daten herunterzuladen.
Mit dieser Methode verwandelst du unübersichtliche Log-Dateien in eine klare, strategische Roadmap. Du siehst genau, welche Themen du ausbauen solltest, um deine Inhalte optimal für KI-Systeme und die generative Suche aufzubereiten. Starte jetzt und verschaffe dir einen entscheidenden Vorteil!

Der „Answerability Score“ im Detail
Der „Answerability Score“ ist das Herzstück unserer Analyse. Er bewertet objektiv, wie gut eine URL dafür strukturiert ist, eine Frage zu beantworten. Die Punktevergabe basiert auf bewährten On-Page-Praktiken:| Feature | Punkte | Warum es wichtig ist |
|---|---|---|
| FAQ-Inhalte | + 2.0 | Du gibst eine Liste von Fragen und präzisen Antworten. |
| Frage in H2-Überschrift | + 1.0 | Eine W-Frage („Was“, „Wie“) signalisiert klar, dass der folgende Absatz eine direkte Antwort liefert. |
| Definitions-Keywords im Titel | + 1.0 | Begriffe wie „Was ist…“, „Definition“ oder „Anleitung“ kommunizieren die Absicht der Seite unmissverständlich. |
| HowTo-Inhalte | + 1.0 | Signalisiert eine klare Schritt-für-Schritt-Anleitung, perfekt für prozessorientierte Fragen. |
| Wortanzahl über 200 | + 0.5 | Stellt sicher, dass der Inhalt genug Substanz hat, um als qualifizierte Antwort zu dienen. |
| Frage in zweiter H2 | + 0.5 | Auch weitere Fragen in untergeordneten Überschriften sind ein positives Signal. |
Strategische Ableitungen: Was mache ich jetzt mit diesen Daten?
Die Analyse liefert dir eine präzise Roadmap. Hier sind drei konkrete Handlungsfelder:
1. Content-Strategie nach echten Themen ausrichten
Die semantische Gruppierung ist der größte Hebel. Du denkst nicht mehr in URL-Ordnern, sondern in echten Themen-Clustern.
- Welche Themen funktionieren? Die Heatmap zeigt dir, welche deiner semantisch erkannten Themen-Cluster bei den KI-Crawlern Anklang finden. Wenn GPTBot deinen Cluster Suchmaschinenoptimierung liebt, ist das ein klares Signal: Produziere mehr tiefgehende Inhalte genau zu diesem Thema – egal, wo sie auf der Website liegen.
- Welche Formate werden bevorzugt? Gibt es eine hohe Korrelation zwischen dem Answerability Score und den Bot-Hits? Dann hast du den Beweis: Dein Weg, Inhalte im Frage-Antwort-Stil zu erstellen und mit strukturierten Daten (FAQ, HowTo) anzureichern, ist goldrichtig und sollte auf alle relevanten Themen-Cluster ausgeweitet werden.
2. Content-Optimierung datengestützt priorisieren
Der „Content-Potenzial“-Report ist deine Blaupause für schnelle Erfolge.
- Wo anfangen? Öffne das Tabellenblatt „Content_Potenzial“ in deinem Excel-Report. Dies ist deine To-do-Liste, intelligent sortiert nach der höchsten Priorität (meiste Bot-Hits bei niedrigem Qualitäts-Score).
- Was tun? Beginne mit den Top-URLs dieser Liste. Dies sind Seiten, für die KI-Systeme bereits ein starkes thematisches Interesse signalisieren, deren Inhalt aber noch nicht optimal aufbereitet ist. Ein klarer Ansatz für deine GEO-Strategie.
- Konkrete Maßnahmen: Überarbeite die H2-Überschriften zu klaren Fragen. Füge einen FAQ-Bereich hinzu (und das passende Schema). Strukturiere den Text besser mit Listen und Tabellen und erhöhe die inhaltliche Tiefe.
3. Nutzer- und Bot-Verhalten endlich abgleichen (mit GSC-Daten)
Wenn du die GSC-Daten integriert hast, kannst du die Brücke zwischen Maschine und Mensch schlagen.
- Finde die versteckten Champions: Filtere deine URL-Level-Tabelle nach Seiten mit vielen Bot-Hits UND vielen Impressionen in der GSC. Das sind die thematisch relevantesten Seiten deiner Website für Mensch und Maschine.
- Optimiere die Klickrate (CTR): Findest du in dieser gefilterten Liste Seiten mit einer niedrigen CTR? Bingo! Das ist das stärkste Signal, sofort Titel und Meta-Description zu optimieren. Der Inhalt ist bereits relevant, aber der „Werbe-Teaser“ in den Suchergebnissen überzeugt noch nicht.
Fazit zu KI-Crawlern und Logfiles
Die Logfile-Analyse ist dein wichtigstes Werkzeug, um das Verhalten von KI-Crawlern wirklich zu verstehen. Während klassische SEO-Tools nur oberflächliche Einblicke liefern, zeigen dir Logfiles, welche Inhalte KI-Systeme tatsächlich abrufen und welche nicht.
Und auch die Optimierung für KI-Crawler wie GPTBot muss kein Blindflug sein. Indem wir Log-Dateien mit Content-Daten kombinieren, schaffen wir eine transparente, datengestützte Grundlage für unsere Content-Strategie. Das hier vorgestellte Skript nimmt dir die technische Arbeit ab und liefert dir direkt die strategischen Einblicke auf dem Silbertablett.
Übrigens: Auch in der GSC lassen sich einige Hinweise auf KI-Crawler finden. Unser Blogartikel „LLM-Spuren in der Google Search Console“ gibt dir konkrete Tipps und Anleitungen zur Analyse.
Weitere Informationen und Quellen zur Logfile-Analyse im Kontext von LLMs
- Dark Visitors: Echtzeit-Analyse von Crawlern (englisch)
- Dark Visitors: Sammlung von Bots inkl. weiterer Informationen (englisch)
- Screaming Frog Log File Analyser (englisch)
- github-Projekt „ai.robots.txt“ zur Sammlung aller KI-Crawler (englisch)
- Sven Giese: Google-Colab-Skript zur Erstellung einer KI-Heatmap für SMART LEMON (deutsch/mehrsprachig)
- Fabian Jaeckert: Logfile Analyse – Wie KI-Bots Ihre Website verarbeiten – auf: jaeckert-odaniel.com am 04. Juli 2025 (deutsch)
- Alex Ramadan, Nick Haigler: Are Log Files the New Impressions? – auf: seerinteractive.com am 13. Mai 2025 (englisch)
- Dan Hinckley: How to See When ChatGPT Is Quoting Your Content – auf: gofishdigital.com am 30. Juni 2025 (englisch)
- Gustavo Pelogia: How to use Screaming Frog + ChatGPT to map related pages at scale – auf: guspelogia.com am 11. Juli 2024 (englisch)
- Studien zur Conversion Rate von KI-Traffic:
- Patrick Stox: (Ahrefs) (englisch)
- Nick Haigler & Garman Chan (Seer Interactive) (englisch)
- Paper von Maximilian Kaiser & Christian Schulze (SSRN) (englisch)

Sven ist ein echtes SMART LEMON Urgestein. Er ist seit 2012 bei uns und war der erste Mitarbeiter der Agentur. Als Head of SEO & GEO leitet er das SEO- & GEO-Team und verantwortet in diesem Bereich das Tagesgeschäft. Außerdem bildet er Kolleg:innen in Sachen Suchmaschinenoptimierung aus. Den Großeltern kann man das so erklären: Sven macht was mit Computern. Und mit Nachdenken 😉