SEO
Googlebot stoppt nach 2 MB: Was die neue Crawl-Grenze für SEO bedeutet
Sven Giese / 16. Februar 2026

- Home
- Blog
- Googlebot stoppt nach 2 MB: Was die neue Crawl-Grenze für SEO bedeutet
Wer Technical SEO lange als „nice to have“ behandelt hat, erhält durch die jüngsten Anpassungen der Googlebot-Dokumentation im Februar 2026 ein deutliches Signal: Googlebot crawlt für Google Search nur noch die ersten zwei MB je Datei. Danach ist Schluss. Alles, was darüber hinausgeht, wird nicht mehr abgerufen und kann folglich nicht sauber für die Indexierung berücksichtigt werden. Das gilt nicht nur für HTML, sondern auch für Ressourcen wie CSS und JavaScript, weil Google sie beim Rendern separat nachlädt.
Das ist keine theoretische Diskussion aus der SEO-Bubble, sondern eine harte technische Grenze, die ab jetzt ganz konkret entscheidet, welche Teile einer Seite Google überhaupt zu sehen bekommt. Wir erklären die technischen Feinheiten dieser Änderungen und geben dir Handlungsanweisungen für deine SEO-Strategien.
TL;DR: Das Wichtigste zum 2MB-Crawl-Limit in Kürze
- Google unterscheidet nun strikt zwischen der allgemeinen Crawling-Infrastruktur (Limit: 15MB) und dem spezifischen Googlebot für die Suche (Limit: 2MB für HTML).
- Das harte 2-MB-Limit für HTML: Für die Google-Suche werden nur die ersten 2MB einer HTML-Datei (unkomprimiert!) berücksichtigt. Inhalte danach werden beim Indexierungsprozess abgeschnitten.
- Ressourcen-Segregation: Jede referenzierte Ressource (CSS, JS) wird als eigener Abruf gewertet und unterliegt ebenfalls dem 2-MB-Limit, zählt also nicht zum Limit der Haupt-HTML-Datei.
- Die PDF-Sonderregelung: PDF-Dateien genießen ein signifikant höheres Limit von 64MB.
Das Googlebot-Update Februar 2026: Infrastruktur und Crawling neu sortiert
Lange war die Google-Dokumentation bezüglich der Dateigrößenlimits eher vage oder an einer zentralen Stelle zusammengefasst, die Raum für Interpretationen ließ. Das Update vom Februar 2026 brachte eine entscheidende Änderung: Google hat die Informationen über Standard-Dateigrößenlimits von der spezifischen Googlebot-Seite in die allgemeinere Dokumentation für Crawler und Fetcher verschoben.
Dieser Schritt mag auf den ersten Blick bürokratisch wirken, ist aber technisch relevant. Denn er signalisiert, dass Google seine „Fetching“-Infrastruktur (also die Serverfarmen und Skripte, die das Internet scannen) als eine breite Plattform betrachtet, auf der verschiedene Produkte aufsetzen.
Hierbei müssen wir zwei Ebenen unterscheiden:
- Die Infrastruktur (Google Crawler und Fetcher): Diese Ebene, zu der diverse Crawler gehören (z. B. AdsBot, Googlebot-Image, APIs-Google), kann standardmäßig Dateien bis zu einer Größe von 15 Megabyte verarbeiten. Dies ist die physikalische Grenze des Abrufsystems. Wenn eine Datei kleiner als 15MB ist, kann sie technisch vom Server geladen und an die nachgelagerten Systeme übergeben werden.
- Das Produkt (Google Suche): Der Googlebot, der speziell für den Suchindex arbeitet, wendet strengere, produktspezifische Filter an. Hier gilt für HTML-Dokumente eine Obergrenze von zwei Megabyte. Alles, was darüber hinausgeht, wird von der Indexierungspipeline ignoriert, obwohl es von der Infrastruktur erfolgreich heruntergeladen wurde.
Für SEO ist diese Unterscheidung zentral. Denn wenn wir in den Server-Logs einen Zugriff von einer Google-IP sehen, der eine 10MB große Datei erfolgreich lädt (HTTP-Status 200), bedeutet das nicht zwingend, dass diese 10MB auch für das Ranking in der Suche verwendet werden. Die Infrastruktur hat lediglich den Download bewältigt, die Indexierungspipeline hingegen läuft Gefahr, nach zwei MB das „Messer anzusetzen“.
Google Crawler-Infrastruktur: Googlebot, Fetcher und ihre Limits
Um das Verhalten des Googlebots zu verstehen, hilft ein Blick auf die Familie der Google-Crawler. Neben dem Googlebot (für die Suche) gibt es diverse Spezialisten.| Crawler-Typ | Beispiel User-Agents | Funktion & Besonderheiten |
|---|---|---|
| Allgemeiner Crawler | Googlebot (Desktop/Smartphone) | Indexierung für die Websuche. Respektiert robots.txt. Limit: 2MB (HTML). |
| Spezial-Crawler | AdsBot-Google, AdsBot-Google-Mobile | Prüft Landingpages für Google Ads. Ignoriert oft robots.txt Disallows, wenn erlaubt. |
| Medien-Crawler | Googlebot-Image, Googlebot-Video | Speziell für Bilder und Videos. Haben oft andere Limits und Parsingeigenschaften. |
| Fetcher | Google-Site-Verification, APIs-Google | Werden durch Nutzeraktionen ausgelöst (z.B. Search Console Bestätigung). |
Interessant ist dabei, dass diese Crawler teilweise unterschiedliche Limits haben können, aber alle auf derselben globalen Infrastruktur basieren. Sie nutzen verteilte Rechenzentren weltweit, um Latenzen zu minimieren.
Das bedeutet bspw. für eine Logfile-Analyse: Ein Zugriff von einer Google-IP ist nicht immer der „Ranking-Bot“. Es könnte auch der AdsBot sein, der prüft, ob eine Landingpage den Richtlinien entspricht. Die Identifikation über den User-Agent-String (und dessen Verifizierung per Reverse-DNS) bleibt daher essenziell.
Was hat Google an der Crawling-Dokumentation geändert?
In der Googlebot-Dokumentation steht seit Anfang Februar 2026 sinngemäß:
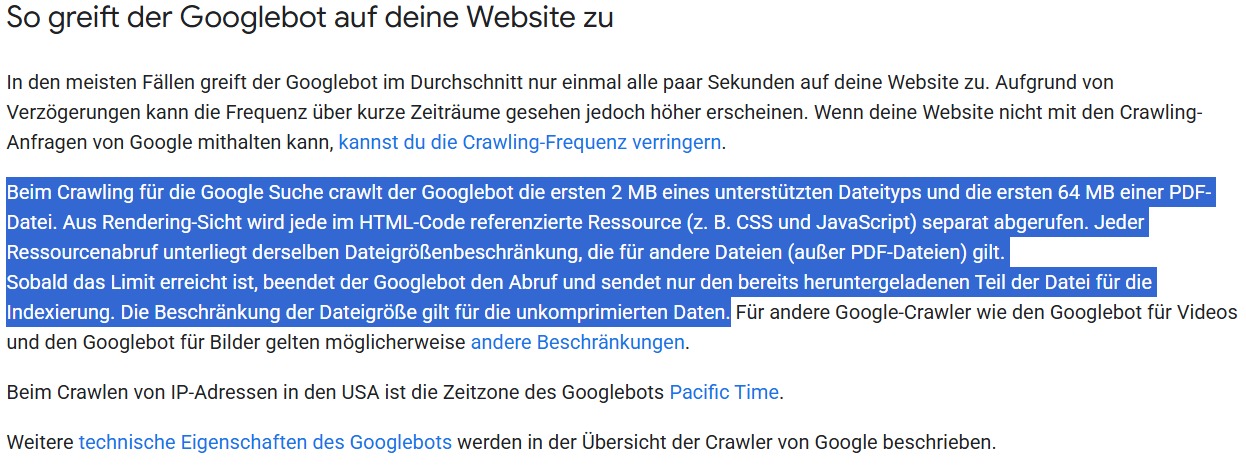
- Googlebot crawlt für Google Search die ersten 2 MB eines unterstützten Dateityps.
- PDFs werden bis 64 MB gecrawlt.
- Jede Ressource (z. B. CSS und JavaScript) wird separat abgerufen und unterliegt dabei demselben Dateilimit.
- Nach Erreichen des Cutoffs stoppt Googlebot den Fetch und nutzt nur den bereits geladenen Teil „for indexing consideration“.
- Das Limit zählt für unkomprimierte Daten.
Google weist weiterhin darauf hin, dass Googlebot bei den meisten Sites „im Schnitt“ nicht öfter als alle paar Sekunden crawlen sollte, und man bei Serverproblemen die Crawl-Rate reduzieren kann Und: Google Search indexiert für die meisten Sites primär die mobile Version, entsprechend kommt der Großteil der Requests vom Smartphone-Googlebot.
Das ist der Punkt, an dem viele Diskussionen schief abbiegen. Denn in der allgemeinen Dokumentation von Googles Crawling-Infrastruktur steht weiterhin: Standardmäßig crawlen Googles Crawler und Fetcher die ersten 15 MB einer Datei, Projekte können aber andere Limits setzen (z. B. je Dateityp). Google Search (Googlebot) hat jetzt offenbar ein deutlich niedrigeres, eigenes Limit (2 MB). Das ist konsistent mit der Aussage, dass einzelne Projekte abweichen dürfen.
Aktuell finden sich auf Social Media mit Hinweis auf den niedrigeren Grenzwert (15 MB auf 2 MB) viele dramatisch klingende Aussagen im Sinne von „Google reduziert Crawl-Limit oder Crawl-Budget“. Aber Vorsicht! Crawl-Budget ist normalerweise eine Diskussion über Menge und Frequenz von URLs. Hier geht es aber primär um etwas anderes: wie viel Byte pro Datei Google überhaupt verarbeitet. Für die Praxis ist es egal, wie man es nennt. Für saubere Kommunikation im Team ist entscheidend.
Übrigens: Ein oft übersehener Aspekt der Crawling-Fähigkeiten ist die Vielfalt der unterstützten Dateiformate. Google ist längst nicht mehr nur auf HTML fixiert. Die Dokumentation (siehe Liste weiterführender Links) listet inzwischen eine umfangreiche Bandbreite auf.
Warum ist das Crawl Limit für SEO und GEO relevant?
Die harte SEO-Realität: Abgeschnitten heißt unsichtbar
Weil „nicht gecrawlt“ in der Praxis fast immer bedeutet: nicht indexiert, nicht verstanden, nicht bewertet. Wenn Googlebot nach zwei MB stoppt, sind die Konsequenzen fataler als ein schlechtes Ranking: Es ist eine Nicht-Existenz. Betroffen sind häufig kritische Elemente, die durch moderne Frameworks an das Ende des Dokuments geschoben werden:
- Hauptcontent: Bei schlechtem LCP-Management rutscht der relevante Text oft unter riesige Header-Bilder und Skripte. Wenn er erst bei Byte 2.000.001 beginnt, existiert er für die Google-Suche nicht.
- Interne Links & Footer: Links in großen Listen, Facetten-Navigationen oder „Related Products“-Sektionen liegen oft am Ende des DOM. Werden sie abgeschnitten, versiegt der Link-Juice. Das Ergebnis: Verwaiste Seiten (Orphan Pages) tief in der Architektur.
- Rendering-Signale: Fehlt das schließende </body> oder </html> Tag oder werden JS-Dateien unvollständig geladen, kann Google die Seite nicht korrekt rendern. Das Layout zerbricht im „Auge“ des Bots.
Die GEO-Dimension: Content als Futter für die KI
SEO wird wieder technischer, weil AI-Systeme harte Grenzen benötigen. Googles AI Overviews (AIO, die KI-Antworten über den Suchergebnissen) oder auch die ChatGPT-Websuche basieren auf RAG (Retrieval-Augmented Generation). Das bedeutet, die KI „halluziniert“ nicht frei, sondern „grounded“ (verankert) ihre Antwort in echten Suchergebnissen. Dafür extrahiert sie Fakten aus den indexierten HTML-Dokumenten.
- Verlust des Grounding: Wenn Googlebot den Teil des HTMLs abschneidet, der einzigartigen Daten oder Fakten enthält, kann die KI deine Seite nicht als Quelle nutzen. Sie werden im AIO nicht zitiert.
- Structured Data als LLM-Währung: Schema.org (JSON-LD) ist die Sprache, die LLMs verstehen. Je nach Implementierung werden diese JSON-Blöcke aber dynamisch in den Footer injiziert. Bei großen E-Commerce-Seiten mit vielen Varianten können diese Blöcke riesig sein. Wird das JSON-LD abgeschnitten, ist die Seite für die KI eher unstrukturiert. Die Chance auf Rich Snippets oder eine Nennung als „Trusted Source“ sinkt.
- Information Gain: KI-Modelle suchen nach „Information Gain“, also Fakten, die andere nicht haben. Wenn diese Fakten im Code-Sumpf untergehen, bewertet Google die Seite als „redundant“.
Wir optimieren also nicht mehr nur für „zehn blaue Links“, sondern im Rahmen von GEO-Strategien auch für die Datenintegrität in einem KI-Ökosystem. Das 2-MB-Limit ist der Türsteher zu diesem Ökosystem.
Googlebot Crawl Limit im Detail: 2 MB für HTML-Dateien
Unkomprimiert vs. komprimiert: Warum die tatsächliche Dateigröße zählt
Ein technisches Detail, das in der Diskussion um Crawling und Fetching häufig untergeht, aber in der Dokumentation explizit erwähnt wird, ist der Zustand der Daten, die durch diese Limitierung betroffen sind. Das Limit von 2MB gilt für die unkomprimierten Daten.
Das ist ein entscheidender Unterschied. Denn moderne Webserver liefern Textinhalte fast immer komprimiert aus (meist via Gzip oder Brotli). Eine HTML-Datei, die über die Leitung („over the wire“) nur 300 Kilobyte groß ist, kann entpackt bereits mehrere Megabyte Text enthalten. Der Prozess aus Sicht des Googlebots läuft wie folgt ab:
- Request: Der Bot fordert die Seite an (HTTP GET).
- Response: Der Server antwortet mit dem komprimierten Stream (z. B. 300KB Gzip).
- Decompression: Googlebot empfängt den Stream und entpackt ihn in seinen Arbeitsspeicher.
- Measurement: Wenn die entpackte Größe 2MB überschreitet, wird der Rest abgeschnitten.
Für die meisten Standard-Websites ist dies kein Problem. Der durchschnittliche HTML-Quelltext einer Seite bewegt sich im Bereich von 30KB bis 100KB (komprimiert oft nur 10KB). Doch bei extrem großen Onepagern, Seiten mit riesigen Inline-SVGs oder – was wir bei Kundenprojekten oft sehen – Seiten, die riesige JSON-Datenblöcke im Quelltext mitführen, kann die 2-MB-Grenze schnell erreicht werden.
Ein Beispiel aus der Praxis: Ein E-Commerce-Shop lädt alle Varianten eines Produkts (Farben, Größen, Preise) als JSON-Objekt in den Quelltext, damit das JavaScript schnell darauf zugreifen kann. Bei einem Produkt mit 500 Varianten kann dieses JSON-Objekt allein schon 1,5MB unkomprimierten Text ausmachen. Addiert man das HTML-Gerüst, Header, Footer und Tracking-Skripte, sind die 2MB schnell überschritten.
Reminder: Crawl-Limit gilt pro Datei
Ein wichtiger Aspekt: Das 2-MB-Limit gilt pro Ressource, nicht für die gesamte gerenderte Seite inklusive aller Bilder und Skripte in Summe. Google erklärt: „Aus der Rendering-Perspektive wird jede im HTML referenzierte Ressource (wie CSS und JavaScript) separat abgerufen, und jeder Ressourcenabruf unterliegt demselben Dateigrößenlimit.” Brechen wir das exemplarisch für die Architektur einer Website herunter, ergibt sich folgende Verteilung:- index.html (1.5MB) -> OK.
- style.css (1.5MB) -> OK.
- app.js (1.5MB) -> OK.
- Gesamtgröße: 4.5MB -> OK, da jede einzelne Datei unter 2MB liegt.
PDF-Crawling: Das 64-MB-Limit als Sonderregel
Während HTML-Seiten und andere Ressourcen an der kurzen Leine von 2MB gehalten werden, gewährt Google PDF-Dateien ein massives Limit von 64 Megabyte.Warum erlaubt Google 64 MB für PDFs? Die historische und technische Begründung
Die Logik dahinter ist in der Natur der Formate begründet. HTML ist das Format des „schnellen Webs“ – dynamisch, oft aktualisiert, modular. Es ist darauf ausgelegt, schnell geparst zu werden. PDFs hingegen sind das Format für „Dokumente“: statisch, oft textlastig, archivierend. Google hat bereits 2001 begonnen, PDFs zu indexieren, und erkannte früh, dass akademische Arbeiten, technische Handbücher und Geschäftsberichte oft als monolithische, große Dateien vorliegen. Ein PDF kann nicht wie eine Webseite in CSS und JS aufgeteilt werden; es ist ein Block.
Google extrahiert den Text aus PDFs (oft mittels OCR, wenn der Text nicht als Text-Layer vorliegt) und behandelt ihn ähnlich wie HTML-Content. Da PDFs oft hochauflösende Bilder enthalten, die die Dateigröße aufblähen, ist das Limit von 64MB notwendig, um sicherzustellen, dass auch der Text am Ende eines 100-seitigen Berichts noch erfasst wird.
PDF-Optimierung: Strategische Nutzung für SEO
Für uns ergibt sich daraus eine klare Strategie für Websites mit extrem umfangreichen Inhalten:
- HTML First: Wenn ein Kunde einen „Ultimate Guide“ mit 50.000 Wörtern plant, ist HTML prinzipiell besser für User Experience und Konversion. Es sollte paginiert oder modular aufgebaut werden, um unter 2MB pro URL zu bleiben.
- Das PDF-Sicherheitsnetz: Sollte der Content jedoch durch unvermeidbare Formatierungen im Quellcode die 2MB sprengen, könnte eine begleitende PDF-Version, die als Download angeboten und indexierbar gemacht wird, sicherstellen, dass der gesamte Textinhalt von Google erfasst wird. Googles John Mueller hat selbst vorgeschlagen, dass für sehr lange Inhalte wie Romane das PDF aufgrund des höheren Limits geeignet sein kann.
- Vorsicht ist geboten: PDFs konvertieren meist schlechter als Webseiten. Die PDF-Strategie sollte nur ein „Backup“ für die Indexierung sein, nicht der primäre Traffic-Treiber. Zudem werden Bilder in PDFs aktuell nicht indexiert; dafür müssten separate HTML-Seiten erstellt werden.
Crawl Budget und Crawl Rate: Mythen vs. Fakten
Ein häufiges Klagelied in SEO-Foren ist der plötzliche Einbruch der Crawl-Statistiken in der Google Search Console. Das ist vor dem Hintergrund der zuvor skizzierten Änderungen allerdings kein Zufall. Denn hinter jeder Reduktion der Crawl-Aktivität steckt eine algorithmische, ökonomische Entscheidung. Googlebot agiert nach einem Prinzip der Ressourcenoptimierung. Er investiert Crawl-Budget (Zeit, Bandbreite, Rechenleistung) dort, wo er:
- Neuen Content erwartet (Aktualisierungsfrequenz).
- Hohe Qualität vorfindet (Relevanz).
- Technische Stabilität garantiert bekommt (Server-Performance).
Wenn die Crawl-Rate sinkt, ist das meist ein Indikator für eines der folgenden Probleme:
- Qualitätsproblem: Google hat festgestellt, dass Updates auf der Seite selten Mehrwert bieten oder die Inhalte qualitativ minderwertig sind (Thin Content), und reduziert die Frequenz der Überprüfung.
- Server-Performance: Der Server antwortet zu langsam (>1000ms), und Googlebot drosselt die Geschwindigkeit, um den Server nicht zu überlasten.
- Technische Blockaden: Fehlerhafte 404s, 500er Fehler oder Soft-404s signalisieren dem Bot eine „Sackgasse“.
Einen Deep Dive zu diesem Thema findest du auch in unserem Beitrag „Google Crawler und Crawl-Budget„.
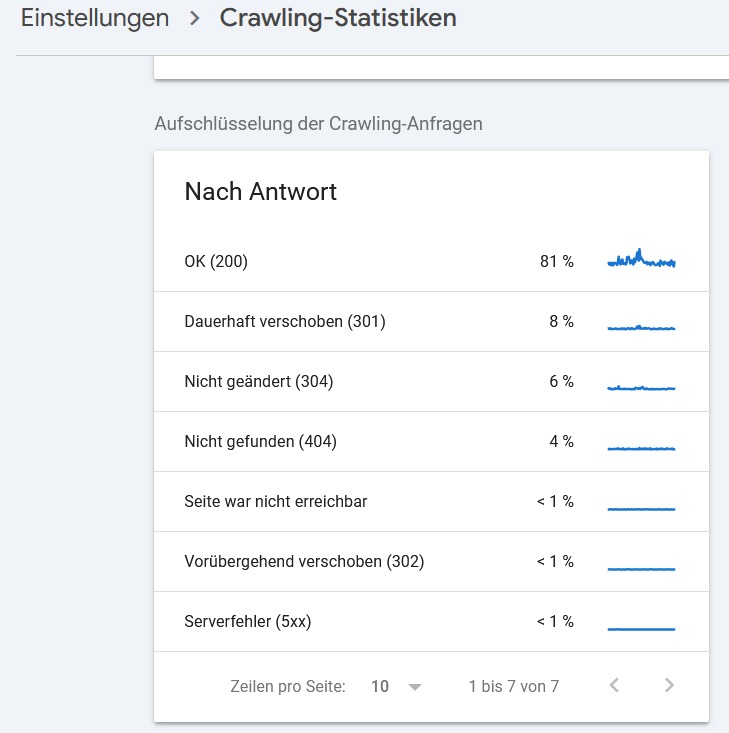
HTTP-Statuscodes und Crawling-Fehler: Was Googlebot erwartet
Die Fähigkeit des Googlebots, auf eine Seite zuzugreifen, steht und fällt mit der Antwort des Servers. In der Dokumentation findet sich der deutliche Hinweis, dass Server- und Netzwerkprobleme die Gründe für die Unverfügbarkeit einer Ressource sind. Übertrieben formuliert: Googlebot ist diesbezüglich eher nachtragend und primär effizienzgetrieben.
- 404/410 (Not Found/Gone): Signalisiert eine nicht gefundene (404) bzw. dauerhaft entfernte Datei (410). Der Bot reduziert die Crawl-Frequenz für diese URL drastisch. Nach einer gewissen Zeit (oft 24h) wird die URL aus dem Index entfernt.
- 5xx (Serverfehler): Signalisiert temporäre Probleme. Wenn Googlebot auf einen 500er, 502er oder 503er Fehler stößt, drosselt er die Crawl-Rate für die gesamte Domain sofort, um den Server zu schonen. Dies ist ein Schutzmechanismus. Gefahr: Ein „kurzer Ausfall“ in der Nacht kann dazu führen, dass Googlebot tagelang vorsichtiger (also seltener) crawlt, was die Indexierung neuer Inhalte verzögert.
- DNS-Fehler: Wenn Googlebot die Domain nicht auflösen kann, ist das für ihn, als existiere die Seite nicht. Dies kann passieren, wenn DNS-Server überlastet sind.
- Soft 404: Eine URL liefert einen 200er-HTTP-Status, zeigt aber eine Fehlermeldung („Produkt nicht gefunden“). Googlebot ist intelligent genug, dies oft zu erkennen, aber es verschwendet Crawl-Budget.
Informationen dazu findest du sowohl im Bereich „Crawling-Statistiken“ der Google Search Console als auch im Indexierungs-Report.
Wichtig: Googlebot crawlt primär von US-IP-Adressen. Wenn ein Server in Deutschland steht und Geo-Blocking für US-IPs aktiviert hat, sperren wir Googlebot (großteils) aus. Ebenso kann eine hohe Latenz (z. B. durch fehlendes CDN für US-Zugriffe) dazu führen, dass Googlebot Timeouts erlebt und die Seite als „nicht erreichbar“ markiert.
Googlebot Crawl Limit: Handlungsempfehlungen für die SEO-Praxis
Wissen ist gut, Handeln ist besser. Um sicherzugehen, dass keine kritischen Rankings durch das 2-MB-Limit gefährdet sind, empfehle ich folgenden pragmatischen Ablauf, den wir auch bei uns nutzen. Dieser Prozess dauert maximal eine Stunde und deckt 90 % der Risiken ab.60-Minuten-Audit: So prüfst du deine Seiten auf Crawl-Limit-Risiken
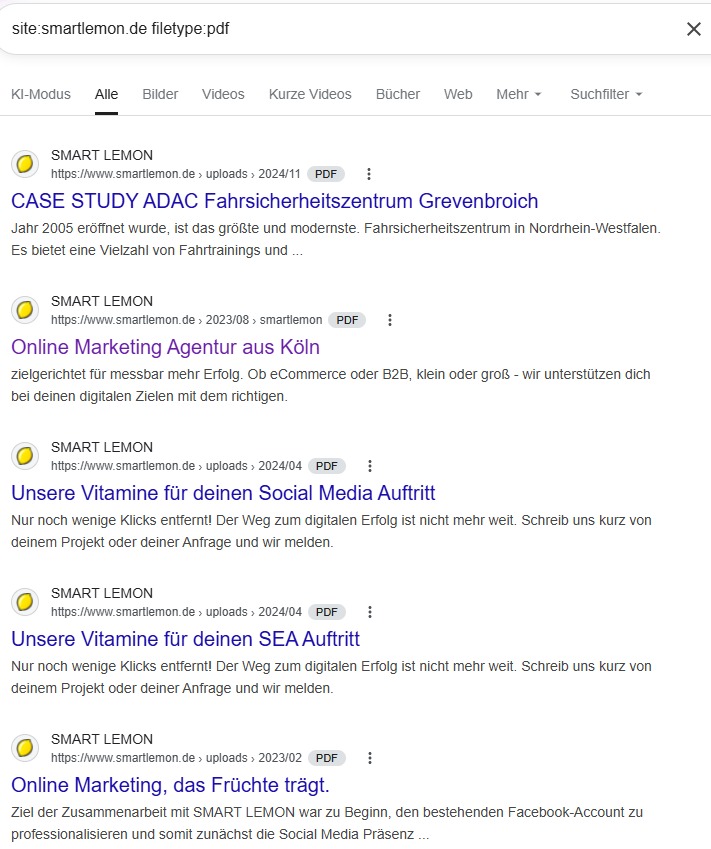
Verlasse dich nicht auf die komprimierte Größe („Transferred Size“) im Browser, die über die Leitung geschickt wird. Für Googlebot zählt die unkomprimierte Größe („Resource Size“).
- Schritt 1: Priorisiere deine Money Pages. Verschwende keine Zeit mit unwichtigen Seiten. Konzentriere dich auf Templates mit hoher SEO-Relevanz (Kategorien, Produkte, umsatzstarke Ratgeber) und solche mit hoher technischer Komplexität (Filter, Infinite Scroll).
- Schritt 2: Miss die unkomprimierte HTML-Größe. Öffne die Chrome DevTools (F12 → Network Tab, siehe unten). Ignoriere die Angabe „Transferred Size“ und prüfe stattdessen die Spalte „Resource Size“. Wenn der Wert deines HTML-Dokuments hier über 2MB liegt, hast du ein akutes Problem. Das Idealziel sollte deutlich unter 100 kB liegen.
- Schritt 3: Prüfe die Ressourcen-Falle. Das 2-MB-Limit gilt pro Datei. Überprüfe separat, ob einzelne JS- oder CSS-Dateien (z. B. app.js, styles.css) ebenfalls über 2MB liegen. Achte bei modernen Frameworks (Next.js, Nuxt) darauf, ob riesige JSON-Datenblöcke für den Initial State im Quelltext liegen. Diese zählen voll zum HTML-Limit.
- Schritt 4: Setze Quick-Wins zur Reduktion um. Wenn du das Limit reißt, helfen diese Maßnahmen oft sofort:
- Ersetze Infinite Scroll durch Pagination (reduziert die DOM-Größe massiv).
- Nutze Code Splitting, um monolithische JS-Bundles in kleinere Chunks aufzuteilen.
- Stelle sicher, dass SEO-relevanter Text (H1, Haupt-Content) weit oben im Quelltext steht, um vor dem 2-MB-Cutoff gesichert zu sein.
- Schritt 5: Validiere in der Search Console. Nutze die URL-Prüfung der Google Search Console. Klicke auf „Live-Test“ und überprüfe den gerenderten HTML-Code, um zu sehen, ob dein Content für Google sichtbar ist und die Größe unter 2MB liegt.
Pro-Tipp: Dateigrößen mit Screaming Frog messen
Viele SEOs öffnen den Screaming Frog und verfallen in Panik, weil sie auf die falsche Spalte schauen. Um das Risiko für das 2-MB-Limit korrekt zu bewerten, müssen wir strikt zwischen Übertragung und entpackter Größe unterscheiden. Hier ist der exakte Arbeitsablauf, um Fehlalarme zu vermeiden:
Die Spalten verstehen
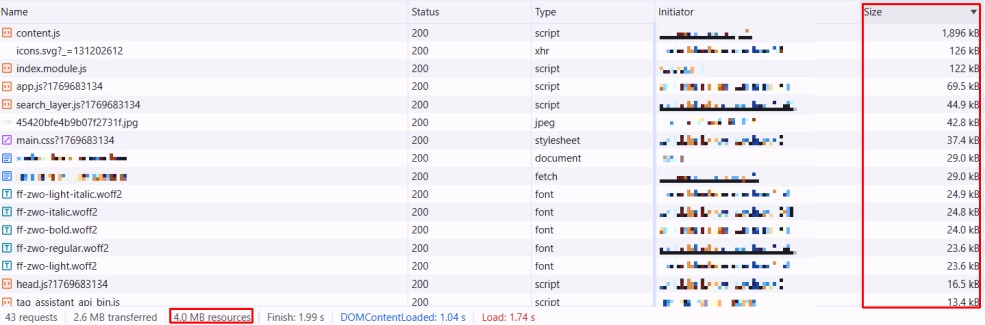
Standardmäßig zeigt Screaming Frog im Tab „Internal“ verschiedene Größenangaben. Für das Googlebot-Limit ist nur eine relevant:
- Transferred (Ignorieren): Das ist die komprimierte Dateigröße (Gzip/Brotli), die über die Leitung ging. Eine 300 KB-Datei hier kann entpackt 2MB groß sein. Wenn du nur hier schaust, unterschätzt du das Risiko.
- Total Transferred (Ignorieren): Das ist die Summe aller Assets (Bilder, JS, CSS), die für die Seite geladen wurden. (sichtbar im JavaScript-Rendering-Modus). Wenn hier „5 MB“ steht, ist das kein Problem für das Indexierungs-Limit, solange keine einzelne Datei die 2MB überschreitet.
- Size (Die Wahrheit): Dies ist die unkomprimierte Größe der Datei (in Bytes). Das ist der Wert, den Googlebot in seinen Arbeitsspeicher lädt und an dem das 2-MB-Limit („Cut-off“) angewendet wird. Nur dieser Wert zählt.
Der Filter-Workflow
Um Risiken in Minuten zu identifizieren, nutze diesen Filter-Weg:
- Crawl starten (mit JavaScript Rendering aktiviert, um auch JS-generierte Links zu finden).
- In den Tab Internal wechseln.
- Filter auf HTML setzen.
- Spalte Size absteigend sortieren.
Alles über 2.000.000 Bytes (ca. 1,9 MB) ist rot. - In den Tab JavaScript wechseln.
Spalte Size sortieren.
Prüfung: Gibt es app.js oder vendor.js Dateien > 2 MB? Wenn ja, ist das ein Problem. - In den Tab CSS wechseln.
Auch hier gilt: Eine einzelne styles.css > 2 MB wird abgeschnitten, was das Rendering bei Google zerstören kann.
Analyse
Wenn deine Startseite eine Total Transferred Size von 8 MB hat, aber die index.html (Size) nur 150 KB, die app.js (Size) 1,5 MB und die Bilder den Rest ausmachen, bist du sicher.
Tipp: Ein exzellentes Looker Studio Dashboard hat der SEO-Kollege Julian Cordes gebaut: Screaming Frog Export inkl. GSC-Daten ziehen, in ein Google Sheet konvertieren und dann in das Dashboard laden. Ergebnis ist eine grafische Aufbereitung:

Strategische SEO-Maßnahmen zur Crawl-Budget-Optimierung
Neben dem akuten Audit solltest du auch das angesprochene Thema des Crawl-Budgets in deine fortlaufende SEO-Praxis integrieren:
- Ressourcen-Management: Prüfe deine robots.txt auf Disallow-Regeln für Verzeichnisse wie /assets/, /css/ oder /js/. Googlebot muss diese Dateien rendern können, um deine Seite korrekt zu verstehen.
- PDF-Optimierung: Wenn du extrem umfangreiche Inhalte (Whitepapers, E-Books) hast, nutze die 64-MB-Ausnahme für PDFs als Indexierungs-Sicherheitsnetz. Stelle dabei sicher, dass deine PDFs textbasiert (keine Bild-Scans) sind und die Metadaten (Titel, Autor) korrekt gesetzt sind.
- Logfile-Analyse als Frühwarnsystem: Reduzierte Crawl-Aktivität ist kein Zufall. Behalte deine Logfiles im Blick. Wenn du eine Drosselung des Googlebots feststellst, überprüfe sofort:
- Haben sich die Antwortzeiten (Time to First Byte) auf über 600ms verschlechtert?
- Gibt es eine Häufung von 5xx-Fehlern (Serverprobleme)?
- Wurde minderwertiger Content („Thin Content“) publiziert, der das Qualitäts-Rating deiner Domain senkt?
Fazit: Schlankes HTML, besseres Crawling – warum weniger mehr ist
Das Februar-2026-Update der Google-Dokumentation ist ein Weckruf für technische Sauberkeit. Das 2-MB-Limit für HTML ist keine willkürliche Schikane, sondern eine Notwendigkeit für ein effizientes, nachhaltiges Web-Ökosystem. Google signalisiert damit: „Wir können nicht alles speichern und verarbeiten. Liefert uns das Wichtigste effizient.“
Für uns als SEOs heißt das: Code-Hygiene ist kein Ranking-Faktor, rückt aber stärker in den Fokus. Aufgeblähte DOM-Strukturen, unnötiges Inline-CSS und riesige Daten-Payloads im HTML sind nicht nur schlecht für die Ladezeit (Core Web Vitals), sie gefährden nun offiziell auch die vollständige Indexierung. Wir müssen lernen, mit dem Budget des Googlebots genauso sparsam umzugehen wie mit unserem eigenen Marketingbudget. Die Zukunft der Suche gehört den schnellen, den strukturierten und den technisch präzisen Seiten.
Weitere Informationen und Quellen zum angepassten Crawl-Limit von Googlebot
- Google Crawling Infrastructure: Overview of Google crawlers and fetchers (user agents) – auf: developers.google.com am 03. Februar 2026 (englisch/mehrsprachig)
- Google Search Central: What Is Googlebot – auf: developers.google.com am 3. Februar 2026 (englisch/mehrsprachig)
- Google Search Central: File Types Indexable by Google – auf: developers.google.com am 3. Februar 2026 (englisch/mehrsprachig)
- Cyrus Shepard: Super-nice catch via Jamie Indigo on Google’s reducing its crawl limit… (Post) – auf: linkedin.com am 5. Februar 2026 (englisch)
- Steve Toth: Google just quietly reduced its crawl limit by 86.7%. – auf: linkedin.com am 5. Februar 2026 (englisch)
- Sven Giese: Googlebot-Limit: 2MB pro Datei. Und das ist für große Sites kein Randthema. – auf: linkedin.com am 5. Februar 2026 (deutsch)
- Barry Schwartz: Google lists Googlebot file limits for crawling – auf: searchengineland.com am 4. Februar 2026 (englisch)
- Google Search Central: In-Depth Guide to How Google Search Works – auf: developers.google.com am 18. Dezember 2025 (englisch/mehrsprachig)
- Gary Illyes: PDFs in Google search results – auf: developers.google.com am 1. September 2011 (englisch/mehrsprachig)
- Jamie Indigo: Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs – auf: speakerdeck.com am 12. Dezember 2025 (englisch)
- Julian Cordes: Looker Studio Dashboard zur Analyse der Seitengröße – auf: linkedin.com am 10. Februar 2026 inklusive direktem Link zum Dashboard (deutsch)

Sven ist ein echtes SMART LEMON Urgestein. Er ist seit 2012 bei uns und war der erste Mitarbeiter der Agentur. Als Head of SEO & GEO leitet er das SEO- & GEO-Team und verantwortet in diesem Bereich das Tagesgeschäft. Außerdem bildet er Kolleg:innen in Sachen Suchmaschinenoptimierung aus. Den Großeltern kann man das so erklären: Sven macht was mit Computern. Und mit Nachdenken 😉