Sichtbarkeit in ChatGPT: So rankst du besser im LLM
Aktualisiert: - Veröffentlicht: - Autor: Sven Giese

- Home
- Blog
- Sichtbarkeit in ChatGPT: So rankst du besser im LLM
Du willst verstehen, warum bestimmte Seiten in ChatGPT-Antworten auftauchen? Deine aber nicht? Dann solltest du dir das JSON hinter jeder Antwort genauer ansehen. Dort zeigt dir ChatGPT konkret, welche Quellen es verwendet, wo dein Content fehlt und wie du gezielt optimieren kannst. Ein aktueller Leak zum ChatGPT-4o-Prompt (Juni 2025) bringt dabei neue Erkenntnisse: ChatGPT nutzt das Web nur in Ausnahmefällen. Konkret: bei Echtzeitthemen, lokalen Anfragen oder extrem spezifischen Fragen. (Gute) Rankings sind also entscheidend, externe Links bleiben die Ausnahme. In diesem Beitrag erfährst du Schritt für Schritt, wie du JSON-Daten abrufst, interpretierst und daraus konkrete Maßnahmen ableitest, um gezielt deine Sichtbarkeit in ChatGPT zu erhöhen.
TL;DR – das Wichtigste in Kürze
- JSON öffnen, Quellen lesen. Per DevTools holst du das komplette Chat-JSON als Basis für die Optimierung in ChatGPT.
- Top-Rankings = Sichtbarkeit. ChatGPT greift nur bei Spezial- oder Echtzeitfragen auf Suchmaschinen wie Google oder Bing zu; ohne Top-Platzierung bleibst du unsichtbar.
- Quellenfelder auswerten. Im JSON-Export erkennst du, ob du als Haupt- oder Nebenquelle zählst und welche Themen du nachbesetzen musst.
- Technik sauber halten. Die JSON-Analyse legt Crawling-Bremsen offen: fehlerhafte Canonicals, JS-Sperren, robots.txt.
- Lücken & 404s clever nutzen: halluzinierte URLs per 301 auffangen und regelmäßiges Monitoring etablieren, um neue Sichtbarkeitschancen zu entdecken.
Einleitende Bemerkung: Rendering-Verhalten von OpenAI
OpenAI nutzt genau drei Crawler (ChatGPT-User, OAI-SearchBot und GPTBot), die jedoch kein JavaScript rendern können. Das heißt: Alles, was nicht als statisches HTML im Quellcode liegt, bleibt daher für die KI unsichtbar. Als Unterstützung ziehen sich die OpenAI-Bots mittlerweile meistens den Suchindex von Google heran. Anfangs wurde fast ausschließlich Bing genutzt. Heißt also generell: Achte darauf, dass deine Inhalte indexiert sind (mehr zum Thema Bing findest du in unserem SEO-Newsletter #22). Dementsprechend gilt es ganz allgemein zu prüfen, ob den OpenAI-Bots in der robots.txt (idealerweise mit Verweis auf die XML-Sitemap) der Zugriff auf die Domain gestattet wird. Mit Blick auf Bing sollte die Nutzung IndexNow-Pings das Ganze beschleunigen. Interessante Beobachtung: Falls vorhanden, ignorieren die Bots llms.txt, da diese Datei primär für Agent-Use-Cases gedacht ist.Update (Juli 2025): Prompt‑Leak bei ChatGPT‑4o – was du jetzt wissen solltest
Im Juni 2025 veröffentlichte James Berry, CEO von LLMrefs, auf LinkedIn den internen System-Prompt von ChatGPT-4o. Die Echtheit wurde von ChatGPT selbst bestätigt (siehe dazu auch die Liste der weiterführenden Links unten). Der Leak liefert interessante Einblicke in die Regeln, nach denen ChatGPT Web-Inhalte überhaupt abruft. Als SEOs interessiert uns natürlich, was sich daraus für Domains und Marken ableiten lässt.
- Rankings entscheiden über Sichtbarkeit. ChatGPT greift auf Google (und Bing)-Ergebnisse zurück, wenn die eigene Datenbasis nicht ausreicht. Genau deshalb ist eine gute organische Platzierung essenziell. Ohne sichtbare Rankings dort hat deine Domain kaum Chancen, bei Live-Suchen in die Antwort zu rutschen. Auch wenn du aktuelle Themen behandelst: ChatGPT greift nur dann auf Live-Suchen zurück, wenn es wirklich notwendig ist. Die Web-API wird nur bei bestimmten Fragearten aktiviert, für die Mehrheit der Prompts bleibt sie inaktiv.
- Crawling ist immer selektiv und situativ gesteuert. Anders als klassische Suchmaschinen crawlt ChatGPT nicht flächendeckend. Der bekannte Browser-Zugriff wurde vollständig deaktiviert. Stattdessen greift ChatGPT auf ein kontrolliertes Web-Tool zurück, das mit festen Parametern wie Boost-Operatoren und einem Frische-Regler („Query Deserves Freshness“) arbeitet. Das LLM aktiviert sein integriertes Web-Tool also nur in Ausnahmefällen. Beispiele hierfür sind: Echtzeitfragen, lokale Themen oder extrem nischige Inhalte, zu denen kaum Trainingsdaten vorhanden sind. In über 90 % der Fälle antwortet ChatGPT allein aus dem Modellgedächtnis. Erschwerend für SEO kommt hinzu, dass die meisten ChatGPT-Antworten auf Quellenverlinkung verzichten. Laut einer SISTRIX-Studie referenzieren lediglich ca. 6 % der Antworten externe URLs. Hier ist die Voraussetzung, dass die Inhalte über ein Top-Ranking verfügen.
- Technisches SEO bleibt die Grundlage. Auch im LLM-Kontext gilt: Ohne saubere technische Basis geht nichts. Wie sich GPTBot, ChatGPT-User oder PerplexityBot tatsächlich auf deiner Website verhalten, zeigen wir ausführlich in unserem Beitrag zur Logfile-Analyse für LLMs und KI-Crawler. Dazu zählen HTML-Struktur, serverseitige Auslieferung ohne JavaScript-Barrieren und eine offene robots.txt. Wer hier schludert, wird vom System übergangen – selbst bei relevantem Content. Vor dem Hintergrund des Crawling-Verhaltens gilt es auch zu beachten, dass ChatGPT keine echten URLs speichert. Stattdessen entstehen vermeintlich echte URL-Strukturen, die häufig einen 404-Status zurückspielen. Wenn du auf Sichtbarkeit über konkrete URLs setzt, solltest du darauf mit passenden Inhalten oder gezielten Weiterleitungen vorbereitet sein. Mehr dazu in unserem Artikel: KI-404-Fehler für SEO nutzen.
- JSON-Analyse macht Unsichtbares sichtbar. Über die DevTools im Browser kannst du nachvollziehen, welche Quellen ChatGPT wirklich nutzt. Die JSON-Ausgabe zeigt dir, ob deine Seite überhaupt als Haupt- oder Nebenquelle berücksichtigt wird – oder ob du mit gezieltem Content nachlegen solltest.
ChatGPT Grounding: So wählt das LLM bei Websuche die passenden Quellen aus
Wenn du nachvollziehen möchtest, wie ChatGPT seine Web-Grounding-Quellen auswählt, lohnt ein Blick unter die Haube. Im Kern läuft dieser Prozess wie folgt ab.
Der Prompt wird zuerst in konkrete Suchanfragen umgewandelt und an Suchmaschinen geschickt. Aus den zurückgelieferten Ergebnissen fischt ChatGPT dann potenziell zur Suchanfrage passende URLs heraus, ruft sie ab, extrahiert deren Inhalte und spielt sie – samt Quellenangabe – in die Antwort ein (siehe dazu auch die gelben Markierungen im unten beigefügten Screenshot).
Ob eine URL in die engere Wahl kommt, entscheidet primär der Mix aus Titel, Meta-Description, Aktualität und Domain-Autorität. Mit den Chrome DevTools lässt sich dieser komplette Workflow im JSON-Response Schritt für Schritt prüfen. Diesen findest du im Folgenden skizziert.

Roh-JSON direkt aus ChatGPT exportieren (Chrome/Edge DevTools)
- ChatGPT in Chrome-Browser öffnen und neuen Chat mit Prompt zur Live-Suche starten.
- Chat-ID kopieren – das ist die lange abschließende Zeichenfolge (=Chat-ID) direkt hinter https://chat.openai.com/…/ in der Adresszeile.
- DevTools öffnen (F12) und auf Inspect gehen.
- Network-Tab auswählen.
- Oben Fetch/XHR aktivieren, damit nur API-Calls auftauchen.
- Die kopierte Chat-ID in das Filterfeld eingeben.
- Den Chat refreshen (Strg + R). Jetzt erscheint ein Request, dessen Name exakt deine Chat-ID trägt.
- Den Request anklicken und im Tab Response das vollständige JSON ansehen. Tipp: Das JSON in einen Editor o.Ä. kopieren, um es einfacher auswerten zu können.
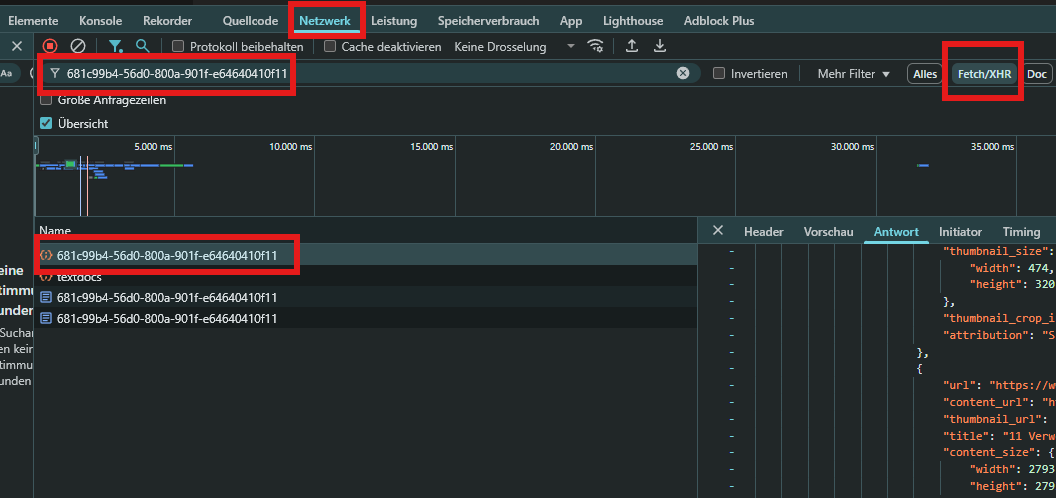
Wichtige Felder im ChatGPT-JSON-File und ihre Bedeutung
- search_results: Alle URLs, die ChatGPT geprüft hat
- sources_footnotes: Die zitierten Hauptquellen
- supporting_websites/safe_urls: Weitere berücksichtigte Seiten
- blocked_urls: URLs, die ChatGPT nicht abrufen konnte oder darf
Damit hast du eine echte Goldgrube: Du erkennst sofort, welche Dokumente die KI nutzt, wo Content-Lücken klaffen und welche Seiten deine klassische PR bislang ignoriert hat.

Strategische Hebel aus dem Chat-JSON: So nutzt du diese Informationen
Damit siehst du exakt, welche Dokumente ChatGPT nutzt, wo Lücken klaffen und welche Seiten klassische PR-Bemühungen bislang verpasst haben. Wie kannst du diese Informationen konkret weiterverarbeiten?
- Content-Gaps schließen: Vergleiche die Felder search_results und sources_footnotes mit deinen eigenen URLs sowie SERP-Rankings. Jede thematische Lücke, bei der ChatGPT Konkurrenzquellen nennt (du aber nicht vorkommst), verdient einen frischen, serverseitig gerenderten Artikel oder eine Erweiterung deines bestehenden Contents. So baust du gezielt Themenautorität auf. Passend dazu auch unser Beitrag: Warum ChatGPT & Co nicht zur Keyword-Recherche taugen.
- Neue Link-& PR-Ziele finden: Analysiere die Domains in supporting_websites nach Häufigkeit – Tools wie Peec AI erledigen das in Serie. Diese „Backup-Quellen“ sind häufig fernab klassischer Medienlisten und damit perfekte Outreach-Kandidaten für hochwertige, thematisch relevante Backlinks.
- Crawl-Blocker entfernen: blocked_urls verraten dir, wo OpenAI (und meist auch Bing) an JS-Sperren, IP-Blocks oder fehlerhaften Canonicals scheitert. Technische Barrieren abbauen, Redirect-Ketten sauber setzen – und die Bots finden deine Inhalte ohne Reibungsverlust. Siehe hierzu auch unseren großen LLM-SEO-Guide.
- Prompt-KPIs aufbauen: Fahr deine Kern-Prompts regelmäßig ab, zieh jedes Mal das JSON und schreib die Daten in ein Sheet oder eine Datenbank. Tracke Kennzahlen wie Häufigkeit deiner Domain, Zitat-Rate oder Rotation der Quellen. So siehst du schwarz auf weiß, welche Optimierungen die KI-Antworten wirklich beeinflussen.
- Halluzinierte URLs nutzen: Wenn ChatGPT wiederholt eine nicht existente URL anruft, lege die Seite an oder leite per 301 auf relevanten Content. Ergänze eine kurze „Warum du hier gelandet bist“-Copy – das verwandelt toten Traffic in echte Leads und signalisiert Trust.
- Holistische Attribute bedienen: Lass ChatGPT offenlegen: „Welche Kriterien bewertest du bei [X]?“. Ergänze genau diese Attribute in Produkt- oder Ratgeberseiten und prüfe im JSON, ob die KI sie wahrnimmt. Je vollständiger dein Content die Erwartungsliste abdeckt, desto öfter wirst du als Quelle zitiert.
Der Blick für Details im JSON oder: Was die weiteren Felder bedeuten und wie du sie nutzt
Beim Auslesen des Chat-JSON tauchen neben den bereits besprochenen Hauptfeldern weitere Parameter auf, die auf den ersten Blick kryptisch wirken, sich aber hervorragend für Feintuning-Analysen eignen:- Felder title, url, snippet, pub_date, attribution: Klassische SERP-Informationen – Achtung: ChatGPT hängt häufig das Tracking-Parameter utm_source=chatgpt.com an deine URLs.
- Feld supporting_websites: Zusätzliche Quellen, die die Aussage deines Dokuments stützen.
- Feld attribution_segments: Interne IDs, die ChatGPT nutzt, um Textstellen im Antwort-Bodies mit Quellen zu verknüpfen.
- Feld refs (z. B. {turn_index: 0, ref_type: „search“, ref_index: 5}): Verweist auf die Position des Dokuments innerhalb des Arrays search_results.
- Felder matched_text, start_idx, end_idx: Marker für die Fußnotensymbole (Unicode-Glyphen wie , ), inklusive Text-Offset im Antwort-String.
- Feld type: „grouped_webpages“: ChatGPT fasst mehrere URLs mit identischem Thema zu einer Gruppe zusammen.
- Feld type: „hidden“: Quellen, die aus Policy-Gründen nicht angezeigt werden, aber intern gewertet sind.
- Felder hue, style, error, status: Rendering-Metadaten – meist für Debugging relevant.

Warum diese Punkte aus SEO-Sicht wichtig sind (…)
Durch die Kombination aus refs → search_results → matched_text kannst du lückenlos nachvollziehen, an welcher Stelle des generierten ChatGPT-Antworttextes deine Seite platziert wird und wie oft sie zitiert oder „nur“ stützend herangezogen wird. Das ist wertvolles Feedback, um Überschriften, H-Tags oder semantische Auszeichnungen exakt dort nachzuschärfen, wo ChatGPT noch alternative Quellen bevorzugt.(…) und wie du diesen Ansatz weiter denken kannst
Drehen wir den Spieß einfach um und bauen uns ein einfaches Python-Skript, das supporting_websites und attribution_segments aller Prompts in eine Tabelle schreibt.
"Help me create a python script that extracts *supporting_websites* and *attribution_segments* (citations) from a batch of ChatGPT JSON response files, writes a tidy CSV table and (optionally) plots the frequency of your domain versus the rest."
Mit diesem Skript lässt sich anschließend:
- Häufigkeit deiner Domain vs. Konkurrenz plotten.
- Themen identifizieren, bei denen du nur als Supporting Source erscheinst.
- Genau an diesen Stellen vertiefen, interne Verlinkung stärken und gezielt Backlinks akquirieren.
Ergebnis: Schrittweise vom „Unterstützer“ zum hauptzitierten Experten werden.
Übrigens: Google setzt mit der Einführung der AI Overviews inzwischen auch auf KI-generierte Antworten in der Suche. Warum das auch deine SEO-Strategie beeinflussen kann, erfährst du in unserem Beitrag.
Fazit: Fünf konkrete SEO-Maßnahmen für LLM-Sichtbarkeit
Ob du in ChatGPT sichtbar bist, entscheidet sich an zwei Stellen: beim technischen Fundament und bei deiner Präsenz in organischen Suchergebnissen. Wer hier nicht liefert, bleibt außen vor, unabhängig von Content-Qualität. Jetzt ist der richtige Zeitpunkt, um deine Strategie auf LLM-Sichtbarkeit auszurichten.
- Der Leak liefert nicht nur Einblicke, sondern auch klare Anhaltspunkte für die Optimierung deiner SEO-Strategie im Umgang mit LLMs.
- SEO hat noch immer oberste Priorität. Denn ohne Top-Rankings bleibst du für ChatGPT (im Web-Modus) unsichtbar.
- Inhalte für Live-Triggerszenarien planen. Produziere Content rund um Themen, die erfahrungsgemäß Live-Suche auslösen: News, Produkt-Launches, lokale Events oder Branchenentwicklungen.
- Technische Basis sauber halten: HTML muss maschinenlesbar sein, ohne dass JavaScript den Zugriff blockiert. Auch eine offene robots.txt für OpenAI-Crawler ist Pflicht.
- 404-Potenzial strategisch nutzen: Wenn ChatGPT fehlerhafte URLs generiert, kannst du per 301-Weiterleitung auf passenden Content umleiten. So holst du dir Trust und Traffic zurück.
- Monitoring für Web-Trigger aufbauen: Tracke, bei welchen Prompts ChatGPT ins Web geht und prüfe, ob du dort präsent bist. Tools wie die oben beschriebene JSON-Analyse helfen, rechtzeitig auf Lücken zu reagieren.
Weitere Hebel zum Thema AI Visibility stellen wir in unserem Artikel „KI-Sichtbarkeit steigern: GEO-Maßnahmen im Praxistest“ vor.
Weiterführende Informationen und Quellen zur LLM-Optimierung und Sichtbarkeit in KI-Antworten
- Oncrawl-Webinar: How to appear in ChatGPT: Practical SEO strategies for AI visibility (englisch)
- Allgemeine Informationen zu ChatGPT Search aus der offziellen Dokumentation (englisch)
- Dokumentation zu Bing IndexNow (englisch)
- Garman Chan und Nick Haigler: Case Study: 6 Learnings About How Traffic from ChatGPT Converts – auf: seerinteractive.com am 3. Juni 2025 (englisch)
- Linkedin-Posting von Johannes Beus: AI Chatbot SEO: Nur wenige Antworten verlinken auf Quellen (deutsch)
- Linkedin-Posting von James Berry zum Leak des ChatGPT-Systemprompts (englisch)
- Untersuchung von Alexis Rylko, ob ChatGPT mittlerweile auf Google statt auf Bing zurückgreift – 6. Juli 2025 (französisch)

Sven ist ein echtes SMART LEMON Urgestein. Er ist seit 2012 bei uns und war der erste Mitarbeiter der Agentur. Als Head of SEO & GEO leitet er das SEO- & GEO-Team und verantwortet in diesem Bereich das Tagesgeschäft. Außerdem bildet er Kolleg:innen in Sachen Suchmaschinenoptimierung aus. Den Großeltern kann man das so erklären: Sven macht was mit Computern. Und mit Nachdenken 😉