GSC + BigQuery = Dream Team – Einrichtung und SQL-Praxisbeispiele
Aktualisiert: - Veröffentlicht: - Autor: Sven Giese

- Home
- Blog
- GSC + BigQuery = Dream Team – Einrichtung und SQL-Praxisbeispiele
Inhaltsverzeichnis
Die Web-Oberfläche der Google Search Console (GSC) ist für schnelle SEO-Checks nützlich, stößt aber mit ihrem 1 000-Zeilen-Limit schnell an Grenzen. Seit Februar 2023 gibt es dafür einen eleganten Ausweg: den Google Search Console Data Connector-Feature (= Bulk-Datenexport). Damit landen deine Performance-Daten täglich und vollautomatisch in BigQuery – ohne jede Beschränkung der Zeilenzahl.
In diesem Beitrag erfährst du Schritt für Schritt, wie du den Connector einrichtest, welche Voraussetzungen nötig sind und welche Fallstricke lauern. Und weil Praxis schlägt Theorie, findest du anschließend konkrete Analyse-Beispiele samt SQL-Code, die zeigen, welches Potenzial im BigQuery-Export steckt.
TL;DR – das Wichtigste in Kürze
Vorteile des Bulk-Exports in BigQuery: Durch Umgehung des 1.000-Zeilen-Limits der GSC stehen vollständige Rohdaten zur Verfügung – essenziell für große Websites und präzise, datengetriebene SEO-Strategien.
Einrichtung Schritt für Schritt: Die Verbindung von GSC mit BigQuery erfolgt über ein Google-Cloud-Projekt, inklusive Rollenvergabe, API-Aktivierung und Export-Konfiguration direkt in der Search Console.
Wichtige Hinweise zur Fehlervermeidung: Häufige Stolperfallen wie fehlende Projektberechtigungen, falsche Projekt-ID oder nicht aktivierte Abrechnung können die Einrichtung verhindern – präzise Prüfung ist essenziell.
Vielfältige SQL-basierte Analysemöglichkeiten: Zahlreiche Abfragebeispiele (u.a. Keyword-Performance, Brand-Traffic, Query-Diversität) zeigen praxisnah, wie sich GSC-Daten tiefgehend und skalierbar auswerten lassen.
Effiziente Performance-Bewertung und Clustering: URLs und Suchanfragen können nach Position, Potenzial und Leistung gruppiert werden – das erleichtert gezielte SEO-Optimierungen und Priorisierung von Inhalten.
Warum sich der Bulk-Export in BigQuery lohnt
Mit dem Bulk-Export der Google Search Console hebelst du gleich zwei Schmerzpunkte der Standard-Oberfläche aus. Erstens entkommst du dem berüchtigten Sampling-Limit: Statt der 1 000 Zeilen (bzw. 50 000 über API/Looker Studio) bekommst du alle Rohdaten. Das ist essenziell für große Sites, die seriöse Modelle, genaue Reportings oder datengetriebene Strategien benötigen. Ein kurzes Beispiel in tabellarischer Form:| Kennzahl | GSC-Frontend (CSV) | GSC-API | BigQuery Bulk-Export |
|---|---|---|---|
| Verschiedene URLs – kleine Domain | 85 | 85 | 85 |
| Verschiedene URLs – große Domain | 1 000 (Limit) | 5000 (API-Limit) | 23 874 |
| Unterschiedliche Keywords – kleine Domain | 980 | 1 240 | 1 240 |
| Unterschiedliche Keywords – große Domain | 1 000 (Limit) | 5000 (API-Limit) | 178 352 |
| Keywords mit Begriff „Brand“ – kleine Domain | 42 | 42 | 42 |
| Keywords mit Begriff „Brand“ – große Domain | 12 | 12 | 894 |
Voraussetzungen zur Verbindung der GSC mit BigQuery
Bevor es losgeht, stelle sicher, dass du Folgendes vorbereitet hast:
- Search Console Property-Zugriff: Du musst Eigentümer der jeweiligen Search Console Property sein, da nur Property-Inhaber den Bulk-Export einrichten können.
- Google Cloud Projekt mit BigQuery: Lege ein Google-Cloud-Projekt an (oder nutze ein bestehendes) und aktiviere die BigQuery APIs darin.
- Stelle sicher, dass für das Projekt die Abrechnung aktiviert ist. BigQuery hat ein kostenloses Kontingent, aber ein hinterlegtes Zahlungskonto ist notwendig, ansonsten schlägt der Export später fehl.
- BigQuery-Berechtigungen: Du benötigst entsprechende Nutzerrechte, um im Cloud-Projekt IAM-Einstellungen zu ändern (Projektinhaber oder -admin). Außerdem solltest du mit grundlegenden BigQuery- und SQL-Konzepten vertraut sein.
Einige Anmerkungen in eigener Sache: Keine Angst vor SQL, viele Anwendungsfälle sind gut dokumentiert und lassen sich im Zweifelsfall in Zusammenarbeit mit ChatGPT & Co relativ leicht für die eigenen Zwecke anpassen. Falls du vorerst keine Möglichkeit hast, die GSC mit BigQuery zu verbinden, empfehlen wir dir eine kostenlose und etwas kompaktere Lösung aus dem SEO-Newsletter #38. Das ist auf jeden Fall besser als gar keine Backups der Daten zu fahren.

Schritt-für-Schritt: GSC-BigQuery-Verknüpfung 🔗
Im Folgenden die Schritt-für-Schritt-Anleitung, wie du deine GSC-Property mit BigQuery in der Google Cloud verbindest:
1) Google Cloud Projekt vorbereiten: Öffne die Google Cloud Console und wähle dein gewünschtes Projekt aus (erstelle ggf. ein neues Projekt). Aktiviere dann die BigQuery API (und BigQuery Storage API) im API-Manager des Projekts.
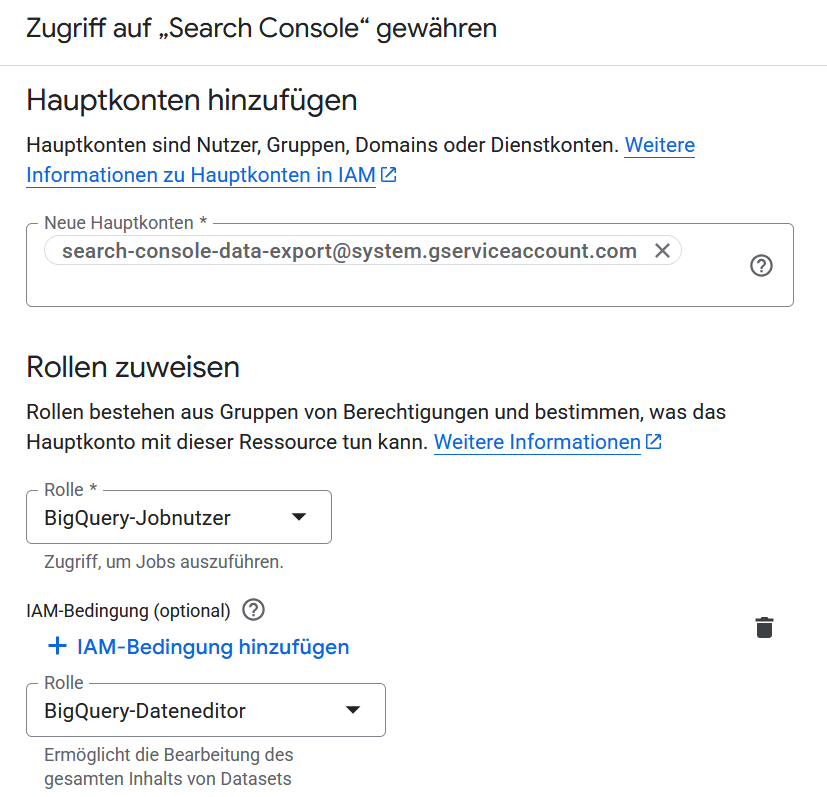
2) IAM-Berechtigung für GSC hinzufügen: Im Cloud Console Menü gehe zu IAM & Verwaltung (IAM). Klicke auf Zugriff gewähren und füge als neuen Principal search-console-data-export@system.gserviceaccount.com hinzu. Weise diesem Dienstkonto zwei Rollen zu: BigQuery-Jobnutzer (BigQuery Job User) und BigQuery-Dateneditor (BigQuery Data Editor). Bestätige mit Speichern. (Hinweis: Dies erlaubt der Search Console, Daten in dein BigQuery zu schreiben.)
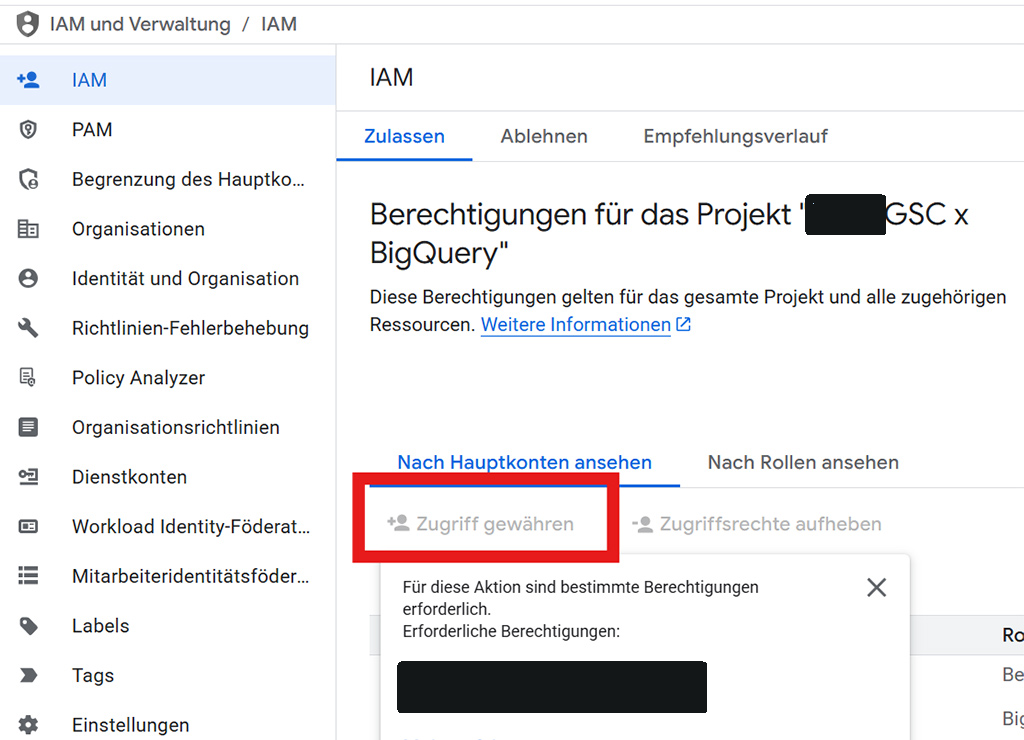
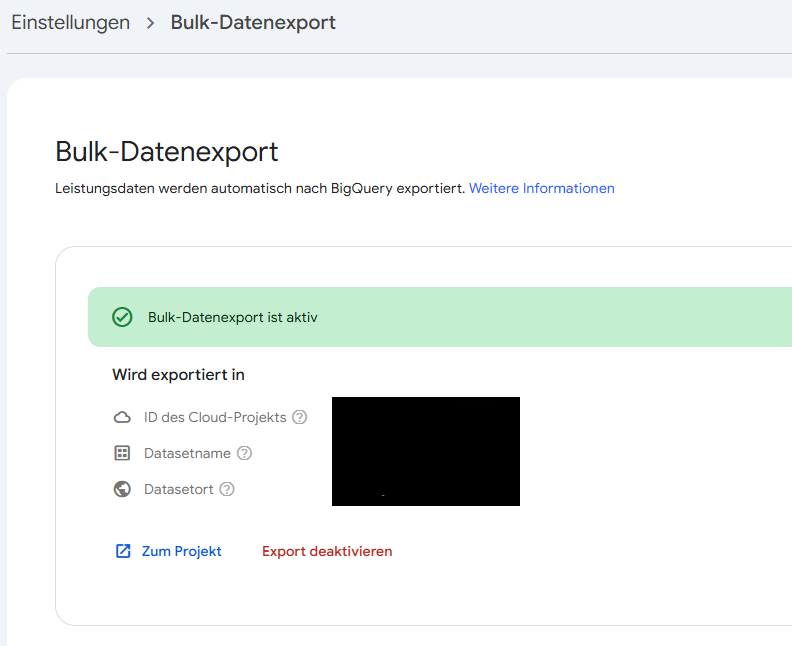
3) Bulk-Export in GSC einrichten: Öffne die Google Search Conosle und navigiere zur entsprechenden Property. Gehe zu Einstellungen > Bulk-Datenexport (Bulk Data Export). Gib dort die Projekt-ID deines Google-Cloud-Projekts ein.
4) Lege einen Dataset-Namen fest. Standardmäßig schlägt Google searchconsole vor; du kannst aber z. B. searchconsole_meineWebsite verwenden, insbesondere wenn du für mehrere Properties Exporte ins selbe Projekt einrichtest (jedes Dataset beginnt immer mit searchconsole als Präfix). Wähle anschließend einen Standort (Location) für das Dataset (z. B. europe-west3 für Frankfurt oder US/EU) und starte den Export mit Weiter/Bestätigen.
5) Ersten Datenimport abwarten: Die Einrichtung ist nun abgeschlossen. Der erste Export erfolgt innerhalb von ca. 48 Stunden, danach täglich. Es werden ausschließlich zukünftige Daten ab dem Einrichtungstag exportiert – frühere historische Daten werden nicht automatisch nachgeladen. Möchtest du ältere Daten in BigQuery haben, musst du sie separat via API importieren.
6) Daten in BigQuery überprüfen: Öffne BigQuery (z. B. im Cloud Console Menü unter BigQuery). Du solltest in deinem Projekt das neue Dataset (z. B. searchconsole_meineWebsite) sehen, darin drei Tabellen:
- searchdata_site_impression – Performance-Daten aggregiert nach Property (Site-Gesamtdaten pro Query/Land/Gerät usw.),
- searchdata_url_impression – Performance-Daten aggregiert nach URL (Daten pro Seite, Query etc.),
- ExportLog – Protokollierung der Exporte (Zeitpunkt, Status). Überprüfe in ExportLog, ob der tägliche Export erfolgreich läuft. Ab jetzt werden täglich neue Zeilen in den Impression-Tabellen hinzugefügt. Du kannst optional eine Partition-Ablaufzeit für die Tabellen setzen (z. B. 12–15 Monate), um unbegrenztes Datenwachstum zu vermeiden, ohne die Tabellenschemata zu verändern (Schema-Änderungen würden die künftigen Importe brechen). Überprüfe im ExportLog, ob der tägliche Export erfolgreich läuft. Ab jetzt werden täglich neue Zeilen in den Impression-Tabellen hinzugefügt. Du kannst optional eine Partition-Ablaufzeit für die Tabellen setzen (z. B. 12–15 Monate), um unbegrenztes Datenwachstum zu vermeiden, ohne die Tabellenschemata zu verändern (Schema-Änderungen würden die künftigen Importe brechen).
Tipps und häufige Stolpersteine ⚠️
- Nur Eigentümer möglich: Stelle sicher, dass du mit einem Search Console-Nutzer arbeitest, der Property-Inhaber ist, sonst siehst du die Option Bulk-Datenexport nicht.
- Projekt-ID vs. Projekt-Nummer: Achte darauf, wirklich die Projekt-ID (human-lesbarer Bezeichner) in Search Console einzutragen, nicht die numerische Projekt-Nummer. Die Projekt-ID findest du oben in der Cloud Console unter Projektübersicht/Projektdetails.
- Berechtigungen korrekt setzen: Wenn der Export nicht startet oder eine Berechtigungs-Fehlermeldung erscheint, prüfe die IAM-Einstellungen. Der Dienstaccount muss exakt so heißen wie oben und beide BigQuery-Rollen zugewiesen haben.
- Abrechnung eingerichtet: Ein häufiger Fehler ist ein nicht verknüpftes Zahlungskonto. Ohne hinterlegte Zahlungsinformationen kann der Bulk-Export nicht eingerichtet werden. Hinterlege also vorab ein Abrechnungskonto für dein Cloud-Projekt, um Fehler zu vermeiden. Falls du die Kosten im Voraus kalkulieren möchtest, bietet Google einen eigenen Rechner (inkl. einem kurzen Tutorial-Video) an.
- Geduld bei erstem Lauf: Nicht wundern, wenn du nicht sofort Daten siehst – der erste Durchlauf kann bis zu 1–2 Tage auf sich warten lassen.
- Datenvolumen & Kosten: Die exportierten Tabellen können bei großen Websites sehr umfangreich werden (mehrere GB). BigQuery-Abfragen kosten je nach gescanntem Datenvolumen Geld. Nutze deshalb die Partitionierung nach Datum zu deinem Vorteil: Beschränke deine Abfragen immer auf den benötigten Datumsbereich (per WHERE data_date …), um Kosten zu sparen.
- Datenstruktur verstehen: Die Search Console exportiert Rohdaten, d. h. es kann für den gleichen Tag und die gleiche Query mehrere Zeilen geben (z. B. aufgesplittet nach Gerät oder Land). Für korrekte Ergebnisse musst du bei Abfragen immer Aggregatfunktionen wie SUM() oder COUNT() verwenden, um die Metriken zu konsolidieren. Außerdem sind die Positionen in den Daten nullbasiert (0 = erste Position); um den gewohnten Durchschnitts-Positionswert zu erhalten, musst du den Berechnungen +1 hinzufügen, falls du sum_top_position verwendest.
- Anonymisierte Suchanfragen: Aus Datenschutzgründen werden seltene Suchanfragen anonymisiert. In den exportierten Tabellen erkennst du sie daran, dass das Feld query leer (Zero-Length String) ist und is_anonymized_query = TRUE gesetzt ist. Laut Google ist diese aggregierte „(other)“ Anfrage oft die häufigste Einzel-„Query“ in den Daten. Bedenke dies bei Analysen – filtere sie ggf. aus, wenn du die Top-Queries ermitteln möchtest.
Praxisbeispiele für SEO-Auswertungen 📈
Sobald die GSC-Daten in BigQuery bereitstehen, kannst du per SQL-Abfragen vielfältige Analysen durchführen. Im Folgenden drei praxisnahe Beispiele + eine Bonusanwendung inklusive kurzer Erläuterung und Beispiel-Code. Hinweis: Ersetze in den SQL-Queries den Platzhalter. deinprojekt.searchconsole. durch die eigene Projekt-ID und den gewählten Dataset-Namen. Dies gilt auch für die genutzten Zeiträume. Grundsätzlich sollten sich die Code-Beispiele problemlos per Copy + Paste in das Abfrage-Terminal von BigQuery kopieren lassen. Klappt das bei dir nicht, kopiere den Code zunächst in einen Text-Editor. Dann werden Formatierungen usw. gelöscht und du kannst das Beispiel von dort aus übernehmen.
Ein erster Überblick: So greifst du bequem auf die neuen Daten zu
Sobald der erste Bulk-Export in BigQuery gelandet ist, könntest du zwar direkt mit eigenen SQL-Statements loslegen – deutlich leichter für einen ersten Überblick ist aber der Weg über Google Looker Studio. Öffne dazu in der Google Cloud Platform den BigQuery-Bereich, wähle dein Dataset und eine der Search-Console-Tabellen aus und klicke auf Abfrage. Ersetze den Vorschlag durch die unten angefügte SQL-Query und führe die Abfrage aus. Anschließend genügt ein Klick auf Öffnen in → Looker Studio: Schon öffnet sich automatisch ein Looker-Studio-Report, in dem du alle Spalten und Zeiträume per Drag-and-drop analysieren kannst. Dies ist die einfachste Methode, um alle Rohdaten zu exportieren und sichtbar zu machen.
SELECT * FROM `deinprojekt.searchconsole.searchdata_url_impression`
1) URL × Query-Tabelle – die allgemeinen GSC-Perfomance-Daten
Erklärung: Wir aggregieren die Search-Console-Rohdaten nach URL und Query. SAFE_DIVIDE fängt Division-durch-Null ab, der Datumsfilter beschleunigt die Abfrage durch Partition-Pruning.
Ergebnis: Du erhältst für jede Seite eine sortierte Liste ihrer stärksten Keywords inklusive aller Kern-KPIs – perfekt, um Keyword-Abdeckung, Long-Tail-Potenzial oder Snippet-Erfolg direkt auf URL-Ebene zu analysieren.
-- ===== Parameter anpassen =================================
DECLARE start_date DATE DEFAULT '2025-04-01';
DECLARE end_date DATE DEFAULT '2025-04-30';
-- ==========================================================
WITH base AS (
SELECT
url,
query,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks,
SUM(sum_position) AS sum_position
FROM `deinprojekt.searchconsole.searchdata_url_impression`
WHERE search_type = 'WEB'
AND query IS NOT NULL
AND data_date BETWEEN start_date AND end_date
GROUP BY url, query
)
SELECT
url,
query,
impressions,
clicks,
SAFE_DIVIDE(clicks, impressions) AS ctr,
SAFE_DIVIDE(sum_position, impressions) + 1 AS avg_position
FROM base
ORDER BY url, clicks DESC;
2) Brand- vs. Non-Brand-Traffic analysieren
a) Detailabfragen zur Unterscheidung von Brand- vs. Non-Brand-Keywords
Ziel: Jedes Keyword soll eindeutig als Markensuche oder generische Suche gekennzeichnet werden, um zu sehen, wie viel deines Traffics wirklich von der Brand kommt und wie viele neue Nutzer bringt.
Erklärung: Eine Regex listet alle Varianten deines Markennamens (bitte anpassen). Treffen diese zu, erhält die Zeile die Kategorie „Marken-Query“, sonst „Andere Query“. Die KPI-Berechnung folgt dem Muster aus der vorherigen Abfrage. Siehe für weitere mögliche Anwendungsmöglichkeiten auch unseren Beitrag zu Regex-Filtern in der Search Console.
Ergebnis: Eine Keyword-Tabelle, die neben Klicks, Impressionen, CTR und Position das Feld „Kategorie“ enthält: „Marken-Query“ oder „Andere Query“. Damit erkennst du sofort, welche Suchbegriffe deine Marke treiben.
-- ===== Parameter ==========================================
DECLARE start_date DATE DEFAULT '2025-04-01';
DECLARE end_date DATE DEFAULT '2025-04-30';
-- Markenbegriffe klein & ohne Sonderzeichen eintragen
DECLARE brand_regex STRING DEFAULT r'(?i)(brandname1|brandname2|brandname3|brandname4)';
-- ==========================================================
SELECT
query,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions,
SAFE_DIVIDE(SUM(clicks), SUM(impressions)) AS ctr,
ROUND(SAFE_DIVIDE(SUM(sum_position), SUM(impressions)) + 1, 1)
AS avg_position,
CASE
WHEN REGEXP_CONTAINS(LOWER(query), brand_regex)
THEN 'Marken-Query'
ELSE 'Andere Query'
END AS kategorie
FROM `deinprojekt.searchconsole.searchdata_url_impression`
WHERE query IS NOT NULL
AND search_type = 'WEB'
AND data_date BETWEEN start_date AND end_date
GROUP BY query, kategorie
ORDER BY kategorie DESC, clicks DESC;
b) Gesamtverhältnis von Brand- vs. Non-Brand-Keywords
Ziel: Auf einen Blick sehen, wie viele Keywords, Klicks und Impressionen insgesamt auf Brand- bzw. generische Suchanfragen entfallen – inklusive prozentualem Klickanteil.
Erklärung: Wir verwenden dieselbe Markenliste wie in Abfrage 2, klassifizieren jede Query und aggregieren anschließend nur noch nach Kategorie. Zusätzlich berechnen wir den prozentualen Klickanteil jeder Gruppe am Gesamtvolumen.
Ergebnis: Eine kompakte Übersicht mit zwei Zeilen („Marke“, „Generisch“), jeweils mit Anzahl der Keywords, Klick- und Impression-Summen, CTR und Klickanteil in %.
-- ===== Parameter ==========================================
DECLARE start_date DATE DEFAULT '2025-04-01';
DECLARE end_date DATE DEFAULT '2025-04-30';
DECLARE brand_regex STRING DEFAULT r'(?i)(brandname1|brandname2|brandname3|brandname4)';
-- ==========================================================
-- 1) Klassifizieren
WITH gsc AS (
SELECT
CASE
WHEN REGEXP_CONTAINS(LOWER(query), brand_regex)
THEN 'Marke'
ELSE 'Generisch'
END AS kategorie,
query,
clicks,
impressions
FROM `deinprojekt.searchconsole.searchdata_url_impression`
WHERE query IS NOT NULL
AND search_type = 'WEB'
AND data_date BETWEEN start_date AND end_date
),
-- 2) Aggregieren
stats AS (
SELECT
kategorie,
COUNT(DISTINCT query) AS anzahl_queries,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions
FROM gsc
GROUP BY kategorie
)
-- 3) KPIs & Anteil
SELECT
kategorie,
anzahl_queries,
clicks,
impressions,
SAFE_DIVIDE(clicks, impressions) AS ctr,
ROUND(100 * SAFE_DIVIDE(clicks,
SUM(clicks) OVER ()), 1) AS klickanteil_prozent
FROM stats
ORDER BY klickanteil_prozent DESC;
3) Top-Performer – Beste Seiten nach Klicks und CTR
Ziel: Welche Landingpages deiner Website erzielen die meisten Klicks über die Google-Suche, und wie hoch ist ihre CTR? Diese Auswertung hilft, die Top-Performer zu identifizieren – also Seiten, die besonders viel Such-Traffic bekommen – und deren Effektivität (CTR) einzuschätzen.
Vorgehen: Wir aggregieren die Search-Performance pro URL über einen Zeitraum und sortieren nach den meisten Klicks. Zusätzlich berechnen wir die Click-Through-Rate (CTR = Klicks/Impressions) jeder Seite. (In der Praxis kann man den Zeitraum einschränken, z. B. letzte 30 Tage, um saisonale Effekte auszublenden.)
Erklärung: Das vorliegende Beispiel betrachtet alle Websuche-Daten im März 2025 (als Beispielzeitraum) und summiert Klicks und Impressionen pro URL. Mit ROUND(…, 2) berechnen wir die CTR in Prozent mit zwei Nachkommastellen. Wir sortieren absteigend nach den Klicks und begrenzen auf die Top zehen Seiten. Das Ergebnis zeigt z. B. die zehn meistgeklickten Seiten deiner Website im betrachteten Zeitraum mit ihren jeweiligen Gesamt-Impressionen und der CTR. So erkennst du, welche Seiten den meisten organischen Traffic bringen und wie effizient sie die Impressionen in Klicks umwandeln. Seiten mit vielen Klicks aber niedriger CTR bieten ggf. Potenzial für Optimierungen (z. B. durch attraktivere Snippets), während Seiten mit hoher CTR besonders relevant für die Nutzer sind.
SELECT
url,
SUM(clicks) AS gesamt_clicks,
SUM(impressions) AS gesamt_impressions,
ROUND(SUM(clicks)/SUM(impressions) * 100, 2) AS ctr_prozent
FROM `deinprojekt.searchconsole.searchdata_url_impression`
WHERE data_date BETWEEN '2025-03-01' AND '2025-03-31' -- Zeitraum anpassen
AND search_type = 'WEB' -- nur Websuche betrachten
GROUP BY url
HAVING SUM(impressions) > 0 -- nur URLs mit Impressionen
ORDER BY gesamt_clicks DESC
LIMIT 10;
4) Query Count – Unique Queries pro URL und Datum
a) Unique Queries pro URL
Ziel: Welche Seiten (URLs) deiner Website liefern die meisten Suchbegriffe? Diese Kennzahl zeigt, welche URLs besonders breit sichtbar sind und als „Traffic-Hubs“ dienen. Je höher der Wert, desto mehr unterschiedliche Suchanfragen führen Nutzer auf diese Seite.
Vorgehen: Wir gruppieren die Search-Console-Rohdaten nach url und zählen mit COUNT(DISTINCT query) die einzigartigen Queries je Seite. Dabei filtern wir nur Web-Suche (search_type = ‚WEB‘) und schließen URLs mit Fragment-Ankern (url NOT LIKE ‚%#%‘) aus, um doppelte Seitenvarianten zu vermeiden. Anonymisierte Queries ohne Text (query = “) kannst du bei Bedarf ebenfalls herausfiltern.
Erklärung: COUNT(DISTINCT query) ermittelt die Anzahl der verschiedenen Query-Strings pro Tag. Durch WHERE query != “ filtern wir Einträge ohne echten Query (die Aggregation der anonymisierten Suchanfragen) heraus, da diese nicht als konkrete Suchbegriffe zählen sollen. Das Ergebnis ist z.B. eine Zeitreihe, die zeigt, an jedem Datum wie viele unterschiedliche Suchanfragen zu Impressionen führten.
SELECT
url,
COUNT(DISTINCT query) AS unique_query_count
FROM
`deinprojekt.searchconsole.searchdata_url_impression`
WHERE
search_type = 'WEB'
AND url NOT LIKE '%#%' -- Fragment-URLs ausschließen
AND query != '' -- anonymisierte Queries rausfiltern (optional)
GROUP BY
url
ORDER BY
unique_query_count DESC;
b) Unique Queries pro Datum/Wochentag
Ziel: Wie viele einzigartige Suchanfragen (Queries) erhält deine Website pro Tag? Diese Metrik zeigt, wie breit gefächert die Sichtbarkeit ist und ob sie im Zeitverlauf zunimmt. Durch tägliche Counts kannst du Trends in der Vielfalt der Suchbegriffe erkennen. Gerade im Kontext der Analyse von Google Core Updates ist dies ein hilfreicher Ansatz.
Vorgehen: Wir zählen die distinct Queries je Datum. Anonymisierte Queries lassen wir weg, da sie keinen Suchbegriff liefern.
Erklärung: COUNT(DISTINCT query) ermittelt die Anzahl der verschiedenen Query-Strings pro Tag. Durch WHERE query != “ filtern wir Einträge ohne echten Query (die Aggregation der anonymisierten Suchanfragen) heraus, da diese nicht als konkrete Suchbegriffe zählen sollen. Das Ergebnis ist z.B. eine Zeitreihe, die zeigt, an jedem Datum wie viele unterschiedliche Suchanfragen zu Impressionen führten.
SELECT
data_date AS datum,
COUNT(DISTINCT query) AS query_count
FROM `deinprojekt.searchconsole.searchdata_site_impression`
WHERE query != '' -- anonymisierte "(other)" Queries ausschließen
GROUP BY datum
ORDER BY datum;
c) Tägliche Counts + kumulativ (Rolling Trend)
Ziel: Zeitreihe statt Schnappschuss: Du willst sehen, wie sich die Zahl der einzigartigen Queries pro URL im Verlauf entwickelt – z. B. täglich oder monatlich. So erkennst du, bei welchen Seiten die Keyword-Vielfalt wächst (Content-Hub, frischer Long-Tail-Traffic) oder schrumpft (Content-Decay, Überoptimierung).
Vorgehen: Nimm die GSC-Export-Tabelle searchdata_url_impression (enthält data_date, url, query, search_type u. a.) und filtere wie gehabt: nur Web-Suche, keine Fragment-URLs, keine anonymisierten Queries (query != ''). Das folgende SQL-Beispiel gruppiert die Daten gleichzeitig nach Zeit-Stempel und URL (GROUP BY data_date, url) und zählt die tägliche Anzahl der vorhandenen Queries für jede URL.
Ergebnis: Eine Zeile je URL × Tag mit Tages-Count und kumulativer Entwicklung – perfekt für Liniendiagramme oder Alerts, wenn der Trend abflacht.
WITH daily AS (
SELECT
data_date,
url,
COUNT(DISTINCT query) AS queries_per_day
FROM
`meinprojekt.searchconsole.searchdata_url_impression`
WHERE
search_type = 'WEB'
AND url NOT LIKE '%#%'
AND query != ''
AND data_date BETWEEN '2025-01-01' AND '2025-04-27' -- Zeitraum anpassen
GROUP BY
data_date, url
)
SELECT
url,
data_date,
queries_per_day,
SUM(queries_per_day) OVER (PARTITION BY url ORDER BY data_date)
AS cumulative_queries
FROM daily
ORDER BY url, data_date;
d) Monatliche Entwicklung als kompakter Pivot-Feed
Sobald du einen größeren Datensatz vorliegen hast, ergibt die Abfrage einer monatlichen Entwicklung al kompakter Pivot-Feed mehr Sinn. Und spart Abfragen. Die folgende SQL-Abfrage zählt mit COUNT(DISTINCT query) pro Zeitfenster die unterschiedlichen Suchanfragen. Durch das gleichzeitige GROUP BY von Datum + URL bekommst du eine Zeitreihe je Seite und die Window-Funktion SUM(...) OVER liefert einen laufenden Gesamtstand – zeigt, ob eine URL im Long-Tail stetig neue Begriffe gewinnt oder stagniert. Über die BETWEEN-Klausel wird das Volumen begrenzt. Spart Kosten und erhöht die Geschwindigkeit.
Ergebnis: Damit hast du die Grundlage, um Query-Diversität nicht nur punktuell, sondern dynamisch zu monitoren und gezielt auf wachsende oder abfallende Seiten zu reagieren. Für jedes Monat/URL-Paar die Query-Vielfalt – ideal zum Pivotieren in Looker Studio, um saisonale Muster oder Content-Wachstum sichtbar zu machen.
SELECT
FORMAT_DATE('%Y-%m', data_date) AS month,
url,
COUNT(DISTINCT query) AS unique_queries
FROM
`meinprojekt.searchconsole.searchdata_url_impression`
WHERE
search_type = 'WEB'
AND url NOT LIKE '%#%'
AND query != ''
AND data_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 12 MONTH) -- letztes Jahr
GROUP BY
month, url
ORDER BY
month, unique_queries DESC;
5) URL-Performance-Scorecard: Potenziale auf einen Blick
Ziel: Ermitteln, welche Landing-Pages deiner Website das größte Klick-Volumen erzielen, wo noch nennenswertes Potenzial schlummert und welche Seiten praktisch gar nicht performen. Die sechs Leistungsklassen Spitzenreiter, Stark, Durchschnitt, Schwach, Potenzial und Lohnt nicht mehr machen es leicht, Content-Prioritäten und Optimierungsaufwand fundiert zu steuern.
Vorgehen: Die CTE aggregated_data reduziert die Daten auf URL-Ebene und verhindert Doubletten. In der Hauptabfrage prüft die CASE-Klausel zuerst die definierten Klick-Schwellen: Mehr als 1 000 Klicks kennzeichnen eine Seite als Spitzenreiter, 101–1 000 Klicks als Stark, 21–100 Klicks als Durchschnitt und 1–20 Klicks als Schwach. Hat eine Seite 0 Klicks, aber über 100 Impressionen, wird sie als Potenzial markiert – hier besteht Reichweite ohne Interaktion; bei 0 Klicks und höchstens 100 Impressionen fällt sie in die Kategorie „Lohnt nicht mehr“. Passe die Schwellenwerte bei Bedarf an dein Traffic-Niveau an, um eine feinere oder gröbere Einteilung zu erhalten.Fragment-URLs (mit „#“) und alles außer Web-Suche werden zuvor ausgefiltert.
Ergebnis: Du bekommst für jede URL eine kompakte Scorecard mit Gesamt-Klicks, Gesamt-Impressions und einer Leistungsklasse von „Spitzenreiter“ bis „Lohnt nicht mehr“. Damit siehst du auf einen Blick, welche Seiten den Löwenanteil des organischen Traffics einfahren, wo noch nennenswertes Potenzial brachliegt (Sichtbarkeit ohne Klicks) und welche Seiten praktisch keine Rolle spielen. Das Ergebnis ist nach Klick-Volumen sortiert, sodass Prioritäten für Optimierung oder Content-Ausbau sofort ersichtlich sind.
WITH aggregated_data AS (
SELECT
url,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions
FROM
`meinprojekt.searchconsole.searchdata_url_impression` -- Tabelle anpassen
WHERE
search_type = 'WEB'
AND url NOT LIKE '%#%' -- Fragment-URLs ausschließen
GROUP BY
url
)
SELECT
a.url,
a.clicks,
a.impressions,
CASE
WHEN a.clicks > 1000 THEN 'Spitzenreiter'
WHEN a.clicks BETWEEN 101 AND 1000 THEN 'Stark'
WHEN a.clicks BETWEEN 21 AND 100 THEN 'Durchschnitt'
WHEN a.clicks BETWEEN 1 AND 20 THEN 'Schwach'
WHEN a.clicks = 0 AND a.impressions > 100 THEN 'Potenzial'
WHEN a.clicks = 0 AND a.impressions <= 100 THEN 'Lohnt nicht mehr'
END AS gruppen_seiten
FROM aggregated_data a
ORDER BY a.clicks DESC;
6) Perfomance auf Positionsbasis clustern
a) Positions‐Buckets pro Query & URL
Ziel: Jede Suchanfrage einer Seite in feste Positionsbereiche einordnen (1-3, 4-10, 11-20 …), um sofort zu sehen, wie viel Traffic noch jenseits der ersten Seite schlummert.
Erklärung: Wir berechnen zunächst für jedes URL-/Query-Paar die durchschnittliche Position und klassifizieren sie anschließend per CASE in Positionsgruppen. SAFE_DIVIDE schützt vor Division-by-Zero, das Datumsfenster ist frei wählbar und filtert Partitionen schon vorab.
Ergebnis: Eine Tabelle mit Query, URL, Positionsgruppe, Klick- und Impression-Summen – sortiert nach Klicks. Damit erkennst du z. B., welche Keywords schon auf Seite 1 ranken und welche im Long-Tail stecken.
-- ===== Parameter ==========================================
DECLARE start_date DATE DEFAULT '2025-04-01';
DECLARE end_date DATE DEFAULT '2025-04-30';
-- ==========================================================
WITH gsc AS (
SELECT
url,
query,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks,
SAFE_DIVIDE(SUM(clicks), SUM(impressions)) AS ctr,
SAFE_DIVIDE(SUM(sum_position), SUM(impressions)) + 1 AS avg_position
FROM `deinprojekt.searchconsole.searchdata_url_impression`
WHERE query IS NOT NULL
AND search_type = 'WEB'
AND data_date BETWEEN start_date AND end_date
GROUP BY url, query
)
SELECT
query,
url,
CASE
WHEN avg_position <= 3 THEN 'Position 1 – 3'
WHEN avg_position <= 10 THEN 'Position 4 – 10'
WHEN avg_position <= 20 THEN 'Position 11 – 20'
WHEN avg_position <= 50 THEN 'Position 21 – 50'
WHEN avg_position <= 100 THEN 'Position 51 – 100'
ELSE 'Position > 100'
END AS positions_bucket,
clicks,
impressions
FROM gsc
ORDER BY clicks DESC;
b) Beste Positions‐Buckets (Totalsicht)
Ziel: Auf aggregierter Ebene herausfinden, welcher Positionsbereich die meisten Keywords, Klicks und Impressionen liefert und wo der größte Hebel für Optimierung liegt.
Erklärung: Wir nutzen die zuvor erzeugten Positionsbuckets und fassen alle Queries je Bucket zusammen. Dadurch sehen wir, ob z. B. Platz 51-100 zwar viele Impressions, aber wenig Klicks liefert – typischer Hinweis auf Keyword-Potenzial kurz vorm Sprung auf Seite 1.
Ergebnis: Eine kurze Scorecard, die je Positionsgruppe die Zahl der Queries, Klick- und Impression-Summen ausweist – sortiert nach Keyword-Anzahl.
-- ===== Parameter ==========================================
DECLARE start_date DATE DEFAULT '2025-04-01';
DECLARE end_date DATE DEFAULT '2025-04-30';
-- ==========================================================
WITH gsc AS (
-- gleiche Basis wie oben
SELECT
url,
query,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks,
SAFE_DIVIDE(SUM(sum_position), SUM(impressions)) + 1 AS avg_position
FROM `mein-projekt.searchconsole.searchdata_url_impression`
WHERE query IS NOT NULL
AND search_type = 'WEB'
AND data_date BETWEEN start_date AND end_date
GROUP BY url, query
),
bucketed AS (
SELECT
query,
CASE
WHEN avg_position <= 3 THEN 'Position 1 – 3'
WHEN avg_position <= 10 THEN 'Position 4 – 10'
WHEN avg_position <= 20 THEN 'Position 11 – 20'
WHEN avg_position <= 50 THEN 'Position 21 – 50'
WHEN avg_position <= 100 THEN 'Position 51 – 100'
ELSE 'Position > 100'
END AS positions_bucket,
clicks,
impressions
FROM gsc
)
SELECT
positions_bucket,
COUNT(DISTINCT query) AS total_query_count,
SUM(clicks) AS total_clicks,
SUM(impressions) AS total_impressions
FROM bucketed
GROUP BY positions_bucket
ORDER BY total_query_count DESC;
7) Anonymisierte Queries analysieren
Ziel: Diese Variante zeigt dir für jeden Tag und jede URL exakt, wie viele anonymisierte Suchanfragen („(other)“-Bucket) in die Leistungswerte eingeflossen sind, inklusive ihrer Klick- und Impression-Summen sowie der erzielten CTR. So erkennst du beispielsweise, welche Landing-Pages besonders viel ungesehenen Long-Tail-Traffic bekommen und ob der Anteil der anonymisierten Queries auf einzelnen Seiten steigt oder fällt.
Vorgehen und Ergebnis: Diese Abfrage liefert dir für jede Kombination aus Tag und Landing-Page einen kompakten Überblick darüber, wie viele anonymisierte Suchanfragen – also die von Google als „(other)“ zusammengefassten Long-Tail-Queries – in die Leistungswerte eingeflossen sind. Dazu greift sie auf die searchdata_url_impression-Tabelle zu, weil dort jede Zeile bereits einer konkreten URL zugeordnet ist.
Im WHERE-Teil werden nur Datensätze ausgewählt, bei denen das Feld query leer ist oder das Flag is_anonymized_query auf TRUE steht; das sind exakt die Zeilen, in denen Google den eigentlichen Suchbegriff aus Datenschutzgründen nicht preisgibt. Anschließend gruppiert die Abfrage gleichzeitig nach Datum und URL. Für jedes dieser Paare wird gezählt, wie viele anonymisierte Query-Zeilen vorkommen, und es werden Klicks sowie Impressionen aufsummiert. Die Click-Through-Rate berechnet sich aus der Division dieser Summen; ein NULLIF verhindert dabei, dass es bei Tagen ohne Impressionen zu einer Division-durch-Null kommt. Optional entfernt ein HAVING impressions_anon > 0 alle Kombinationszeilen, in denen zwar ein anonymer Datensatz existiert, aber keine Impressionen vorliegen – solche Fälle sind für die Analyse in der Regel irrelevant.
Sortiert wird nach Datum und absteigend nach anonymen Impressionen, sodass du sofort erkennst, an welchen Tagen und auf welchen Seiten besonders viel Long-Tail-Traffic unter dem Radar läuft. Das Ergebnis erlaubt dir, die Bedeutung anonymisierter Queries für einzelne URLs zeitlich zu verfolgen und gezielt Seiten zu identifizieren, auf denen viel Reichweite verschenkt wird, weil die konkreten Suchbegriffe verborgen bleiben.
SELECT
data_date AS datum,
url,
COUNT(*) AS anonymisierte_queries,
SUM(clicks) AS clicks_anon,
SUM(impressions) AS impressions_anon,
ROUND(SUM(clicks) /
NULLIF(SUM(impressions),0) * 100, 2) AS ctr_anon_prozent
FROM
`meinprojekt.searchconsole.searchdata_url_impression` -- Dataset anpassen
WHERE
search_type = 'WEB'
AND (query = '' OR is_anonymized_query = TRUE) -- nur "(other)"-Zeilen
AND data_date BETWEEN '2025-03-01' AND '2025-03-31' -- Zeitraum anpassen
GROUP BY
datum, url
HAVING
impressions_anon > 0 -- optional: reine 0-Zeilen kappen
ORDER BY
datum,
impressions_anon DESC;
Fazit
Mit dem Google Search Console Bulk-Datenexport nach BigQuery steht SEOs ein mächtiges Werkzeug zur Verfügung, um Suchperformance-Daten detailliert auszuwerten. Von Trend-Analysen über einzigartige Suchanfragen bis zu Tiefenanalysen der Top-URLs – all das lässt sich nun automatisiert und skalierbar umsetzen. So macht die Analyse und Nutzung der Google Search Console gleich noch mehr Spaß. 😉 Viel Erfolg bei der Umsetzung und Analyse! 📊🚀
Weiterführende Informationen und Quellen zu GSC und Big Query

Sven ist ein echtes SMART LEMON Urgestein. Er ist seit 2012 bei uns und war der erste Mitarbeiter der Agentur. Als Head of SEO & GEO leitet er das SEO- & GEO-Team und verantwortet in diesem Bereich das Tagesgeschäft. Außerdem bildet er Kolleg:innen in Sachen Suchmaschinenoptimierung aus. Den Großeltern kann man das so erklären: Sven macht was mit Computern. Und mit Nachdenken 😉