Share of Model: Marktanteil in KI-Antworten messen
Aktualisiert: - Veröffentlicht: - Autor: Sven Giese

- Home
- Blog
- Share of Model: Marktanteil in KI-Antworten messen
Inhaltsverzeichnis
Share of Model (SoM)? Wer in der klassischen SEO Marktanteile misst, kennt den Share of Voice als prozentualen Anteil der eigenen Sichtbarkeit an der gesamten Suchnachfrage eines Themas.
Mit dem Aufstieg der Generative Engine Optimization stellt sich dieselbe Frage in einem neuen Kontext: Wie oft empfiehlt eine KI eine Marke, wenn jemand in diesem Themenfeld fragt? Und wie schlägt sich die Marke dabei im Vergleich zum Wettbewerb? Die Antwort liefert der Share of Model als wichtigste KPI, den die meisten Marketing-Teams aktuell nicht systematisch erheben.
TL;DR: Das Wichtigste zum Share of Model als GEO-KPI
- Share of Model (SoM) misst den prozentualen Anteil einer Marke an allen Markennennungen eines KI-Modells innerhalb eines definierten Themenclusters: analog zum Share of Voice, aber für KI-Empfehlungen.
- Verschiedene KI-Plattformen funktionieren grundlegend anders: ChatGPT nennt wenige Marken und stärkt das Branding, Google AI Overviews verlinkt häufiger und erzeugt Traffic. Ein plattformübergreifender Gesamt-SoM ist deshalb irreführend.
- Den SoM verbesserst du langfristig durch Earned Media in Fachpublikationen, klar strukturierte und zitierbare Inhalte sowie thematische Konsistenz über alle Kanäle hinweg.
Was ist der Share of Model? Definition und Abgrenzung zu Share of Voice
Der Share of Model (SoM) ist die direkte KI-Adaption des klassischen Share of Voice. Er misst, wie groß der prozentuale Anteil deiner Marke an allen Markennennungen eines KI-Modells innerhalb eines definierten Themenclusters ist:
Share of Model = (Nennungen der eigenen Marke ÷ Gesamtzahl aller Markennennungen im Cluster) × 100
Der entscheidende Unterschied zur klassischen Metrik: Während der Share of Voice auf Google-Rankings basiert, also auf Positionen in einer Ergebnisliste, misst der SoM eine aktive Empfehlungshandlung. Eine KI nennt eine Marke, weil das Modell sie für relevant hält. Das verändert die Logik der Sichtbarkeit fundamental.
Ein konkretes Beispiel verdeutlicht das, eines, das wir bei SMART LEMON naturgemäß selbst im Blick haben. Auf Basis von 100 identischen Prompts ergibt sich folgendes Bild:
ChatGPT nennt durchschnittlich 2,4 Marken pro Antwort. Das macht 240 Nennungen im Gesamtpool:
| Agentur | Nennungen | SoM |
|---|---|---|
| Domain 1 | 52 | 21,7 % |
| Domain 2 | 41 | 17,1 % |
| Domain 3 | 38 | 15,8 % |
| SMART LEMON | 34 | 14,2 % |
| Domain 4 | 28 | 11,7 % |
| Weitere | 47 | 19,6 % |
Google AI Overviews ist großzügiger: Durchschnittlich 6,0 Nennungen pro Antwort ergeben 600 Nennungen im Gesamtpool:
| Agentur | Nennungen | SoM |
|---|---|---|
| Domain 1 | 89 | 14,8 % |
| Domain 2 | 78 | 13,0 % |
| Domain 5 | 67 | 11,2 % |
| Domain 4 | 61 | 10,2 % |
| Domain 3 | 55 | 9,2 % |
| SMART LEMON | 48 | 8,0 % |
| Weitere | 202 | 33,7 % |
Was zeigt dieser Vergleich? Obwohl SMART LEMON bei Google AIO in absoluten Zahlen häufiger auftaucht (48 vs. 34 Nennungen), ist der Share of Model dort nur halb so hoch. Die Erklärung: Google AIO teilt den Kuchen auf deutlich mehr Agenturen auf. Die relative Wettbewerbsposition ist bei ChatGPT stärker, obwohl die absolute Sichtbarkeit bei Google AIO höher liegt. Beide Werte erzählen eine unterschiedliche Geschichte und genau deshalb benötigst du beide zur zielgeführten Messung.
Warum du Share of Model pro KI-Plattform separat messen musst
Wichtig zu wissen: Ein aggregierter SoM über alle Plattformen hinweg ist nicht nur ungenau, sondern aktiv irreführend. Der Grund liegt in den unterschiedlichen Mechanismen, nach denen die großen KI-Plattformen Marken empfehlen. Eine Analyse von BrightEdge (August 2025), basierend auf zehntausenden identischen Prompts, dokumentiert eine Diskrepanz von 61,9 % bei den Markenempfehlungen zwischen ChatGPT, Google AI Overviews und Google AI Mode: Nur 17 % der Anfragen lieferten auf allen drei Plattformen dieselben Marken.
Die Ursache sind die unterschiedlichen Persönlichkeiten der Plattformen:
- ChatGPT agiert wie ein klassischer Markenempfehler: Es nennt im Schnitt 2,4 Marken pro Antwort und bevorzugt historisch etablierte Marken mit starker Präsenz in den Trainingsdaten. ChatGPT erwähnt Marken 3,2-mal häufiger, als es sie verlinkt. Der Wert liegt also primär im Branding, kaum im direkten Traffic.
- Google AI Overviews verfolgt den umgekehrten Ansatz. Mit durchschnittlich 6,0 Nennungen pro Anfrage verteilt es seinen Marken-Kuchen breiter, verlinkt aber gleichzeitig 2,4-mal häufiger, als es bloß erwähnt. Die Citation Rate ist hier das stärkere Signal für tatsächliche Reichweite.
- Google AI Mode ist am selektivsten: Weniger Marken schaffen es in die Antworten, aber diejenigen, die genannt werden, profitieren von starker Zitationsunterstützung.
Was bedeutet das praktisch für deine GEO-Strategie? Du benötigst für jede Plattform einen eigenen SoM-Wert, idealerweise ergänzt um die jeweilige Citation Rate, also ob die Marke aktiv verlinkt oder nur passiv erwähnt wird. Wer diese Unterscheidung nicht macht, optimiert möglicherweise auf das falsche Ziel.
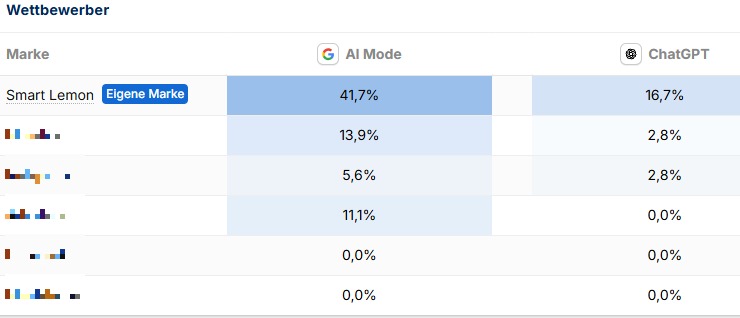
Screenshot: Share of Voice für den AI Mode und ChatGPT im SISTRIX Prompt-Tracker
So erhebst du den Share of Model in der Praxis: 4 Schritte
Der Share of Model lässt sich ohne spezialisierte Tools erheben, wenn du methodisch vorgehst. Diese vier Schritte bilden die Grundlage (Quelle: SparkToro/Fishkin, 2026, sowie Peec AI, Otterly.AI):
- Prompt-Set definieren. Erstelle 10 bis 20 repräsentative Prompts für dein Themencluster. Die besten Ausgangspunkte sind reale Nutzeranfragen aus der Google Search Console, klassische Keyword-Recherchen oder Plattformen wie AnswerThePublic. Die Prompts sollten abbilden, wie deine Zielgruppe tatsächlich fragt. Nicht, wie du selbst über dein Angebot sprichst.
- Stichprobe durchführen. Jeden Prompt mindestens 30-mal pro Modell ausführen. SparkToro empfiehlt 60 bis 100 Durchläufe für statistisch robuste Werte. Bei weniger Durchläufen sind die Schwankungen zu groß, um belastbare Trends zu erkennen.
- Nennungen vollständig zählen. Erfasse nicht nur die erstgenannte, jede einzelne Nennung in der Antwort. Inklusive Position und Art (bloße Erwähnung vs. aktiver Link). Die Position in der Antwort beeinflusst die Wahrnehmung: Wer immer an erster Stelle steht, profitiert anders als wer zuletzt genannt wird.
Regelmäßig wiederholen. Monatliche Benchmarks sind das Minimum. In dynamischen Branchen oder nach Modell-Updates empfehlen sich wöchentliche Stichproben. Für die operative Umsetzung gibt es spezialisierte Tools: Peec AI, Otterly.AI und SISTRIX automatisieren weite Teile des Prozesses und liefern Dashboards mit Verlaufsdaten.
Wie du deinen Share of Model aktiv verbesserst
Ein niedriger SoM ist kein Urteil, sondern ein Ausgangspunkt. Was beeinflusst eigentlich, ob und wie oft ein KI-Modell eine Marke nennt? Drei Hebel haben sich in der Praxis als besonders wirksam erwiesen (Quelle: Johannes Beus, sistrix.de, 2025):
- Earned Media und Erwähnungen in glaubwürdigen Quellen. KI-Modelle wie ChatGPT trainieren auf großen Textkorpora. Redaktionelle Erwähnungen in Fachmedien, Branchenberichten und Studien spielen darin eine überproportionale Rolle. Wer in relevanten Publikationen zitiert, analysiert oder empfohlen wird, erhöht die Wahrscheinlichkeit, dass das Modell diese Assoziation übernimmt. Klassische PR-Arbeit und Thought Leadership werden damit zu einem direkten GEO-Hebel.
- Strukturierte, zitierbare Inhalte auf der eigenen Website. Google AI Overviews und Google AI Mode bevorzugen Quellen, die sie direkt verlinken können. Das setzt voraus, dass deine Inhalte klar strukturiert, eindeutig zuordenbar und inhaltlich präzise sind. Faktenpages, Studien, Definitionen und klar formulierte Positionierungen geben KI-Systemen die Anker, die sie für eine Zitation benötigen. Vage Marketingtexte funktionieren hier nicht.
- Konsistenz über Kanäle und Zeit. KI-Modelle spiegeln wider, was in ihren Trainingsdaten dominant und konsistent präsent ist. Eine Marke, die über Jahre hinweg konsequent zu einem Thema publiziert, zitiert wird und in einschlägigen Kontexten auftaucht, hat strukturelle Vorteile gegenüber Marken mit sporadischer Sichtbarkeit. Das ist kein Sprint, sondern ein Aufbau. Ähnlich wie Domainautorität im klassischen SEO, nur auf Themenebene.
Wichtig: Diese Maßnahmen wirken nicht von heute auf morgen. KI-Modelle werden in Zyklen trainiert; Veränderungen im SoM sind oft erst nach mehreren Monaten messbar. Umso wichtiger ist es, frühzeitig mit dem Tracking zu beginnen und Maßnahmen langfristig anzulegen.
Mehr Tipps? Kostenlosen SMART LEMON SEO-Newsletter abonnieren!
Share of Model im Kontext: das vollständige GEO-KPI-Set
Der Share of Model ist ein mächtiger Indikator, aber keine Universallösung. SoM misst ausschließlich eine relative Position im Wettbewerb innerhalb eines Modells. Erst alle KPIs bilden gemeinsam ein vollständiges Bild der KI-Sichtbarkeit:
- Detection Rate ist die technische Grundvoraussetzung des gesamten Sets: Sie prüft, ob das Modell deine Marke auf direkte Nachfrage überhaupt korrekt identifiziert. Eine Detection Rate von null macht jeden anderen KPI-Wert schwer interpretierbar.
- Visibility Percentage misst, in wie viel Prozent der Prompts deine Marke überhaupt auftaucht, unabhängig von Position oder Häufigkeit. Sie ist die Voraussetzung für alle anderen KPIs.
- Share of Model setzt deine Nennungen ins Verhältnis zur nGesamtzahl aller Markennennungen im Cluster und zeigt deine relative Wettbewerbsposition.
- Citation Rate geht einen Schritt weiter und fragt, in wie vielen dieser Antworten deine Marke als klickbarer Link oder Fußnote ausgegeben wird. Sie ist der entscheidende Faktor für tatsächlichen Traffic aus KI-Antworten.
- Sentiment Score bewertet, ob die KI deine Marke positiv empfiehlt, neutral erwähnt oder kritisch einordnet. Er ist die qualitative Ergänzung zur quantitativen Visibility.
Für SEO-Verantwortliche und Marketing-Teams, die ihr Reporting auf Generative Engine Optimization ausweiten wollen, gilt daher: Richtet das Tracking dieser GEO-Metriken modellspezifisch ein, bevor ihr in inhaltliche Optimierungsmaßnahmen investiert. Ohne Baseline wisst ihr nicht, ob eure Maßnahmen wirken.
Du möchtest wissen, wie deine Marke aktuell in KI-Antworten abschneidet? Wir messen deinen Share of Model modellspezifisch auf ChatGPT, Google AI Overviews und Google AI Mode und zeigen, wo die größten Hebel liegen. Sprich uns an.
Häufige Fragen zum Share of Model
Was ist der Unterschied zwischen Visibility Percentage und Share of Model?
Die Visibility Percentage misst, ob deine Marke überhaupt in den Antworten eines KI-Modells auftaucht. Sie ist eine binäre Größe auf Prompt-Ebene. Der Share of Model geht einen Schritt weiter: Er setzt deine Nennungen ins Verhältnis zur Gesamtzahl aller Markennennungen im selben Themencluster und macht damit deine relative Wettbewerbsposition sichtbar. Beide Metriken zusammen beantworten die Fragen „Bin ich dabei?“ und „Wie stark bin ich dabei?“.
Was ist die Citation Rate und warum ist sie relevant?
Die Citation Rate beschreibt, wie oft ein KI-Modell deine Marke aktiv im Verhältnis zu den Gesamtnennungen verlinkt. Eine hohe Citation Rate bedeutet, dass die KI deine Inhalte aktiv als Quelle verlinkt. Das ist besonders bei Google AI Overview entscheidend, da diese Plattform 2,4-mal häufiger verlinkt als bloß erwähnt.
Was sagt der Sentiment Score aus?
Der Sentiment Score bewertet die Tonalität der KI-Nennungen: Wird deine Marke positiv empfohlen, neutral erwähnt oder kritisch eingeordnet? Er ist die qualitative Ergänzung zum quantitativen SoM. Ein Unternehmen mit hohem SoM und negativem Sentiment hat möglicherweise ein Reputationsproblem in den Trainingsdaten. Das ist ein grundlegend anderes Problem als ein niedriger SoM bei positivem Sentiment.
Wie lange dauert es, bis Optimierungsmaßnahmen den SoM messbar verbessern?
Das hängt vom Trainingsrhythmus des jeweiligen Modells ab. Und der ist in der Regel nicht öffentlich dokumentiert. Als grobe Orientierung gilt: Veränderungen werden frühestens nach zwei bis drei Monaten messbar, häufig erst nach einem größeren Modell-Update. Deswegen ist eine frühzeitige Baseline entscheidend: Wer heute mit dem Tracking beginnt, kann spätere Verbesserungen belastbar nachweisen.
Weitere Informationen und Quellen zu Citation Rate und Detection Rate
- Kai Spriestersbach: KI-Empfehlungen sind ein Glücksspiel: Was die neue SparkToro-Studie für GEO bedeutet – auf: afaik.de am 19. Februar 2026 (deutsch)
- Leigh McKenzie: Generative engine optimization (GEO): How to win AI mentions – auf: searchengineland.com am 11. Februar 2026 (englisch)
- Burcu Aydoğdu: How to Measure Generative Engine Optimization (GEO)? KPIs & Reporting for AI Visibility – auf: analyticahouse.com am 5. Februar 2026 (englisch)
- Rand Fishkin: NEW Research: AIs are highly inconsistent when recommending brands or products – auf: sparktoro.com am 27. Januar 2026 (englisch)
- Johannes Beus: Der Weg zur AI-Citation: Was die 100 meistzitierten Webseiten richtig machen – auf: sistrix.de am 13. November 2025 (deutsch)
- Brightedge: ChatGPT vs. Google AI: 62% Brand Recommendation Disagreement – auf: brightedge.com am 27. August 2025 (englisch)
- Ben Wood: Share of Model: a key metric for AI-powered search – auf: allam.agency am 7. Juli 2025 (englisch)

Sven ist ein echtes SMART LEMON Urgestein. Er ist seit 2012 bei uns und war der erste Mitarbeiter der Agentur. Als Head of SEO & GEO leitet er das SEO- & GEO-Team und verantwortet in diesem Bereich das Tagesgeschäft. Außerdem bildet er Kolleg:innen in Sachen Suchmaschinenoptimierung aus. Den Großeltern kann man das so erklären: Sven macht was mit Computern. Und mit Nachdenken 😉